

Have you ever wondered how to gather vast amounts of data from the web efficiently and effortlessly? If so, you’ve come to the right place! Welcome to the ultimate guide to web scraping with Python. In this tutorial, we will explore the fascinating world of Python web scraping and uncover its countless applications.
First things first, let’s demystify Python web scraping. What exactly is it? We’ll delve into the definition and provide real-life examples of web scraping to extract valuable information from websites. You may wonder why Python is preferred for web scraping projects.
We’ll uncover the reasons behind Python’s popularity in the web scraping community and explore its powerful libraries and tools specifically designed for this task. To kickstart your web scraping journey, we’ll walk you through the step-by-step process of scraping data with Python.
We’ve got you covered, from inspecting the targeted web page and sending HTTP requests to extracting specific sections and storing data in various formats like CSV and JSON. We’ll also discuss the possibility of utilizing APIs for web scraping projects and introduce you to Zenscrape. Let’s embark on this exciting adventure of web scraping Python tutorial together!
What Is Web Scraping?
Web scraping refers to the extraction of data from websites automatically. It involves writing code to navigate web pages, retrieve specific information, and store it for analysis or further use. Moreover, web scraping enables users to gather large amounts of data quickly and efficiently.
Web Scraping Use Cases
The use cases for web scraping are diverse and abundant. Here are just a few examples in our Python web scraping tutorial:
Market Research
Scraping e-commerce websites to gather product details, prices, and customer reviews for competitive analysis and pricing strategies.
Data Aggregation
Extracting data such as news articles, blog posts, or social media posts for content curation, sentiment analysis, or trend monitoring.
Lead Generation
Scraping business directories or social media platforms to collect contact information. It includes email addresses or phone numbers for sales and marketing purposes.
Financial Analysis
Gathering stock market data, company financials, or economic indicators from various sources to make informed investment decisions.
Academic Research
Collecting data from research publications, scientific journals, or educational websites for analysis and data-driven insights.
Real Estate Analysis
Scraping property listings and market data to analyze trends, pricing, and investment opportunities in the real estate sector.
Why Should You Choose Python For Web Scraping Project?
Python is one of the best programming languages for web scraping projects. Here are several reasons why it’s an excellent choice:
Python’s simplicity lets developers quickly grasp the fundamentals and scrap websites without extensive coding knowledge.
Python offers powerful libraries and frameworks specifically designed for web scrapings, such as BeautifulSoup, Scrapy, and Requests.
It has a large and active community of developers. The community is always ready to assist and share their knowledge.
It is a cross-platform language, meaning you can run your web scraping scripts on different operating systems like Windows, macOS, or Linux without major modifications.
Python integrates with popular data analysis and visualization libraries such as Pandas, NumPy, and Matplotlib.
Python offers frameworks like Flask and Django to help you build robust applications around your scraping code.
Can We Use APIs for Web Scraping Projects Through Python?
APIs can be the most reliable sources for performing web page scraping. There are multiple reasons behind it. Let’s explore one of the most popular APIs for web scraping, Zenscrape.
Zenscrape
Zenscrape can help your businesses grow faster with ease in web scraping projects. Since the API is built with advanced technology, it handles all web scraping problems. Moreover, it also guarantees highly reliable HTTP requests.
Here are the features of Zenscrape:
JavaScript code rendering
Fair pricing
Location-based results
High concurrency
Automatic Proxy Rotation
Supports all frontend frameworks
How To Start Scraping Data Through Python?
Here are some steps that you should follow to perform web scraping using Python.
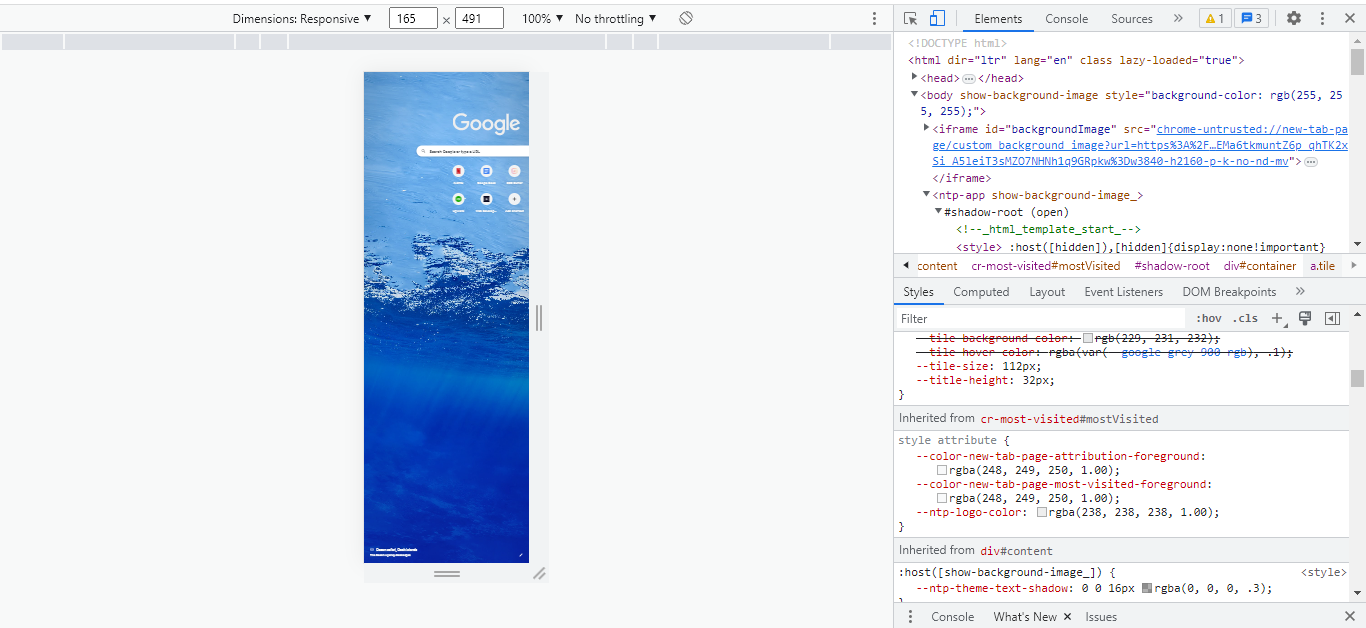
Inspect the Targeted Page
In this step, you inspect the HTML code of your website to gain an idea of its structured data. Here is an example of what you get after clicking on inspect.
Send an HTTP Request
First, you must install the libraries. “Requests” is the most common web-scraping Python library to extract data from web servers.
pip install requests #installation of requests library for web scraping in pythonSuppose our targeted web page is a Wikipedia page with publicly available data. Then our code will look like the below.
import requests #import the library that you installed in previous step
URL = 'https://en.wikipedia.org/wiki/Beer' #insert your targeted URL here
page = requests.get(URL)Scrape the Page HTML
To parse the HTML result we got from the above code, you have to install the Beautifulsoup object library.
pip install beautifulsoup4 #installation of beautiful soup library for web scraping in pythonLet’s format our results first.
import requests
from bs4 import BeautifulSoup
def get_pretty_html(url):
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
pretty_html = soup.prettify()
return pretty_html
URL = 'https://en.wikipedia.org/wiki/Beer'
prettyHTML = get_pretty_html(URL)
print(prettyHTML)Extraction of Specific Sections
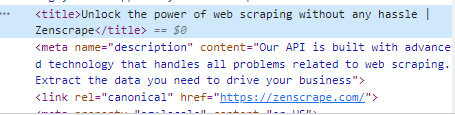
Sometimes, we only need specific data from our HTML tags. For example, the title of the website. You can find it inside the <head> section within the <title> tags.
Let’s take our previous example regarding the Wikipedia page. If we want to extract data from a particular tag, we can use the following example code.
import requests
from bs4 import BeautifulSoup
def extract_title(soup):
title = soup.find('title')
print('Title element: ', title)
print('Title: ', title.text)
def scrape_website():
URL = 'https://en.wikipedia.org/wiki/Beer'
page = requests.get(URL)
soup = BeautifulSoup(page.content, 'html.parser')
extract_title(soup)
scrape_website()If we want to extract elements occurring more than once, we use the .find_all() method.
import requests
from bs4 import BeautifulSoup
def extract_images(soup):
images = soup.find_all('img')
for image in images:
imageAlt = image.get('alt')
imageSrc = image.get('src')
print("ALT: ", imageAlt, "SRC: ", imageSrc)
def main():
URL = 'https://en.wikipedia.org/wiki/Beer'
page = requests.get(URL)
soup = BeautifulSoup(page.content, 'html.parser')
extract_images(soup)
if __name__ == "__main__":
main()Passing Functions While Scraping
Suppose we want only the internal links of a web page. But we get all the data in the output. To filter out the data inside the web scraping project, we use the lambda() function.
Let’s take an example. We will scrape data from a website with its internal links, articles, and summaries of each article. We will target href attribute to get links.
Install the libraries.
pip install -U nltkImport it inside the code.
import re
import nltk
import heapq
nltk.download()Here is the code.
count = 0
def can_do_summary(tag):
global count
if count > 10:
return False
if not tag.parent.name == 'p':
return False
href = tag.get('href')
if href is None:
return False
if not href.startswith('/wiki/'):
return False
compute_summary(href)
return True
def extract_links(soup):
soup.find_all(lambda tag: tag.name == 'a' and can_do_summary(tag))
def main():
URL = 'https://en.wikipedia.org/wiki/Beer'
page = requests.get(URL)
soup = BeautifulSoup(page.content, 'html.parser')
extract_links(soup)
main()The above code gives us internal links. While the following code will give us summaries of articles.
import requests
from bs4 import BeautifulSoup
import re
import nltk
import heapq
def compute_summary(href):
global count
full_link = 'https://en.wikipedia.org' + href
page = requests.get(full_link)
soup = BeautifulSoup(page.content, 'html.parser')
# Concatenate article paragraphs
paragraphs = soup.find_all('p')
article_text = ""
for p in paragraphs:
article_text += p.text
# Removing Square Bracket, extra spaces, special characters, and digits
article_text = re.sub(r'\[[0-9]*\]', ' ', article_text)
article_text = re.sub(r'\s+', ' ', article_text)
formatted_article_text = re.sub('[^a-zA-Z]', ' ', article_text)
formatted_article_text = re.sub(r'\s+', ' ', formatted_article_text)
# Converting text to sentences
sentence_list = nltk.sent_tokenize(article_text)
# Find frequency of occurrence of each word
stopwords = nltk.corpus.stopwords.words('english')
word_frequencies = {}
for word in nltk.word_tokenize(formatted_article_text):
if word not in stopwords:
if word not in word_frequencies:
word_frequencies[word] = 1
else:
word_frequencies[word] += 1
maximum_frequency = max(word_frequencies.values())
for word in word_frequencies:
word_frequencies[word] = (word_frequencies[word] / maximum_frequency)
# Calculate the score of each sentence
sentence_scores = {}
for sent in sentence_list:
for word in nltk.word_tokenize(sent.lower()):
if word in word_frequencies:
if len(sent.split(' ')) < 30:
if sent not in sentence_scores:
sentence_scores[sent] = word_frequencies[word]
else:
sentence_scores[sent] += word_frequencies[word]
# Pick top 7 sentences with the highest score
summary_sentences = heapq.nlargest(7, sentence_scores, key=sentence_scores.get)
summary = '\n'.join(summary_sentences)
count += 1Store Data Inside a CSV File
At this point, you don’t need to install anything. You can use the following code to store data within a CSV file.
import csv
summaries_file = open('summaries.csv', mode='a', encoding='utf-8')How To Perform Web Scraping By Using Zenscrape?
Zenscrape allows web scraping in Python easily. You can also go for a proxy mode when using Zenscrape. Here is a Python code example by Zenscrape.
import requests
headers = {
"apikey": "YOUR-APIKEY"}
params = (
("url","https://httpbin.org/ip"),
("premium","true"),
("country","de"),
("render","true"),
);
response = requests.get('https://app.zenscrape.com/api/v1/get', headers=headers, params=params);
print(response.text)
Web Scraping With Python: Conclusion
We have explored the ultimate guide to web scraping with Python, uncovering the ins and outs of this powerful technique. We’ve covered the essentials, from understanding web scraping and its various use cases to delving into why Python is the preferred language for scraping projects.
We walked through the step-by-step process of scraping data using Python, including inspecting web pages, sending HTTP requests, and extracting specific sections. We’ve also explored storing data in different formats like CSV format.
Additionally, we discussed the possibility of using APIs for web scraping projects and introduced Zenscrape as a valuable tool for simplifying the scraping process.
Armed with this knowledge, you can embark on your web scraping journey. So go ahead, explore the vast world of web data, and unlock the endless possibilities that web scraping with Python offers. Happy scrapping!
FAQs
Is Python Good for Web Scraping?
Yes, Python is excellent for web scraping due to its simplicity, extensive libraries, and strong community support.
Is Web Scraping API Legal?
The legality of web scraping APIs depends on the website’s terms of service and the applicable laws in your jurisdiction.
What Is the Best Web Scraping Tool for Python?
Zenscrape is the best web scraping tool.
Which Is Better, Scrapy or Beautifulsoup?
The choice depends on the project. Scrapy is ideal for large-scale, complex scraping, while BeautifulSoup is simpler and better for small tasks.