

The World Wide Web is full of a wide variety of useful data for human consumption. However, this information is usually difficult to access programmatically, especially if it does not come as RSS feeds, APIs, or other formats.
With Java libraries like jsoup and HtmlUnit, you can easily harvest and parse this information from web pages and integrate them into your specific use case—such as for recording statistics, analytical purposes, or providing a service that uses third-party data.
In this article, we’re going to talk about how to perform web scraping using the Java programming language.
What you’ll need
What we’ll cover
- Using jsoup for web scraping
- Using HtmlUnit for web scraping
Ready?
Let’s get going…
Using jsoup for web scraping
jsoup is a popular Java-based HTML parser for manipulating and scraping data from web pages. The library is designed to work with real-world HTML, while implementing the best of HTML5 DOM (Document Object Model) methods and CSS selectors.
It parses HTML just like any modern web browse does. So, you can use it to:
- Extract and parse HTML from a string, file, or URL.
- Find and harvest web information, using CSS selectors or DOM traversal techniques.
- Manipulate and edit the contents of a web page, including HTML elements, text, and attributes.
- Output a clean HTML of a web page
Here are the steps to follow on how to use jsoup for web scraping in Java.
jsoup is a popular Java-based HTML parser for manipulating and scraping data from web pages. The library is designed to work with real-world HTML, while implementing the best of HTML5 DOM (Document Object Model) methods and CSS selectors.
It parses HTML just like any modern web browse does. So, you can use it to:
- Extract and parse HTML from a string, file, or URL.
- Find and harvest web information, using CSS selectors or DOM traversal techniques.
- Manipulate and edit the contents of a web page, including HTML elements, text, and attributes.
- Output a clean HTML of a web page
Here are the steps to follow on how to use jsoup for web scraping in Java.
1. Setting up jsoup
Let’s start by installing jsoup on our Java work environment.
You can use any of the following two ways to install jsoup:
- Download and install the
jsoup.javafile from its website here. - Use the jsoup Maven dependency to set it up without having to download anything. You’ll need to add the following code to your
pom.xmlfile, in the<dependencies>section:
<dependency>
<!-- jsoup HTML parser library @ https://jsoup.org/ -->
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.13.1</version>
</dependency>
Then, after installing the library, let’s import it into our work environment, alongside other utilities we’ll use in this project.
2. Fetching the web page
For this jsoup tutorial, we’ll be seeking to extract the anchor texts and their associated links from this web page.
Here is the syntax for fetching the page:
Document page = Jsoup.connect("https://www.waterless-toilet.com/top-6-best-composting-toilets-to-choose/").get();jsoup lets you fetch the HTML of the target page and build its corresponding DOM tree, which works just like a normal browser’s DOM. With the parsable document markup, it’ll be easy to extract and manipulate the page’s content.
This is what is happening on the code above:
- jsoup loads and parses the page’s HTML content into a Document object.
- The
Jsoupclass uses theconnectmethod to make a connection to the page’s URL. - The
getmethod represents the HTTP GET request made to retrieve the web page
Furthermore, the Jsoup class, which is the root for accessing jsoup’s functionalities, allows you to chain different methods so that you can perform advanced web scraping or complete other tasks.
For example, here is how you can imitate a user agent and specify request parameters:
Document page = Jsoup.connect("<target_web_page").userAgent("Mozilla/5.0 (Windows NT 6.1; rv:80.0) Gecko/27132701 Firefox/78.7").data("name", "jsoup").get();3. Selecting the page’s elements
After converting the HTML of the target page into a Document, we can now traverse it and get the information we are searching for. jsoup uses a CSS or jQuery-like selector syntax to allow you to find matching elements.
With the select method, which is available in a Document, you can filter the elements you want. The select method returns a list of Elements (as Elements), providing you with a variety of methods to retrieve and work on the results.
Here’s the syntax for selecting all the hyperlinks on the target web page:
Elements pageElements = page.select("a[href]");4. Iterating and extracting
Lastly, after selecting the hyperlinks, it’s now time to iterate and extract their content.
Here is the code that runs through each hyperlink on the target web page and outputs their texts and href attributes to the console:
Optionally, you can use jsoup to implement a proxy and avoid being blocked or throttled when extracting data from websites. With a versatile proxy service, such as datacenter proxies or residential proxies, you can hide your real IP address and circumvent the anti-scraping measures established by most popular websites.
5. Adding proxies
To set up a proxy using Jsoup, you’ll need to provide your proxy server details before connecting to a URL. You’ll use the setProperty method of System class to define the proxy’s properties.
Here is an example of how to set up a proxy:
//set HTTP proxy host to 147.56.0.11
System.setProperty("http.proxyHost", "147.56.0.11");
//set HTTP proxy port to 2071
System.setProperty("http.proxyPort", "2071");If a proxy server requires authentication, you can define it this way:
System.setProperty("http.proxyUser", "<insert_username>");
System.setProperty("http.proxyPassword", "<insert_password>");Wrapping up
Here is the entire code for using the jsoup library for scraping the content of a web page in Java:
If we run the above code, here are the results we get (for brevity, we’ve truncated the results):
Link: https://www.waterless-toilet.com/category/waterless-toilets-benefits/
Text: Technology
Link: https://www.waterless-toilet.com/category/waterless-toilets-technology/
Text: Tips
Link: https://www.waterless-toilet.com/category/tips/
Text: Reviews
Link: https://www.waterless-toilet.com/category/reviews/
Text: Shop
Link: https://www.waterless-toilet.com/shop/
Text: Home
Link: https://www.waterless-toilet.com/
Text: Reviews
Link: https://www.waterless-toilet.com/category/reviews/It worked!
Using HtmlUnit for java web scraping
While jsoup is great for web scraping in Java, it does not support JavaScript. So, it may not yield the desired results if you use it to scrape a web page with dynamic content or content added to the page after the page has loaded.
Therefore, if you want to extract data from a dynamic website, HtmlUnit may be a good alternative.
HtmlUnit is a Java-based headless web browser that comes with several functionalities for manipulating websites, invoking pages, and completing other tasks—just like a normal browser does.
Here are the steps to follow on how to use HtmlUnit for web scraping in Java.
1. Setting up HtmlUnit
You can use any of the following two methods to install HtmlUnit on your Java work environment:
- Download and install the HtmlUnit files from here.
Use the HtmlUnit Maven dependency to set it up without having to download anything. You’ll need to add the following code to your pom.xml file, in the <dependencies> section.
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>2.41.0</version>
</dependency>Then, after installing HtmlUnit, let’s import it into our work environment, alongside other utilities we’ll use in this project.
2. Initializing a headless browser
In HtmlUnit, WebClient is the root class that is used to simulate the operations of a real browser.
Here is how to instantiate it:
WebClient webClient = new WebClient();The above code will create and initialize a headless browser with default configurations.
If you want to imitate a specific browser, such as Chrome, you can pass an argument into the WebClient constructor.
Providing a specific browser version will alter the behavior of some of the JavaScript as well as alter the user-agent header information transmitted to the server.
For example, here is how to specify a browser version:
WebClient webClient = new WebClient(BrowserVersion.CHROME);3. Configuring options
Optionally, you can use the getOptions method, which is provided by the WebClient class, to configure some options and increase the performance of the scraping process.
For example, here is how to set up insecure SSL on the target web page:
webClient.getOptions().setUseInsecureSSL(true);Here is how to disable CSS:
webClient.getOptions().setCssEnabled(false);This is how to disable JavaScript:
webClient.getOptions().setJavaScriptEnabled(false);Finally, this is how to disable exceptions for JavaScript:
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);4. Fetching the web page
For this HtmlUnit tutorial, we’ll be seeking to extract the posts’ headings on this Reddit page, which uses JavaScript for dynamically rendering content.
Here is the syntax for fetching the page:
HtmlPage page = webClient.getPage("https://www.reddit.com/r/scraping/");5. Selecting the page’s elements
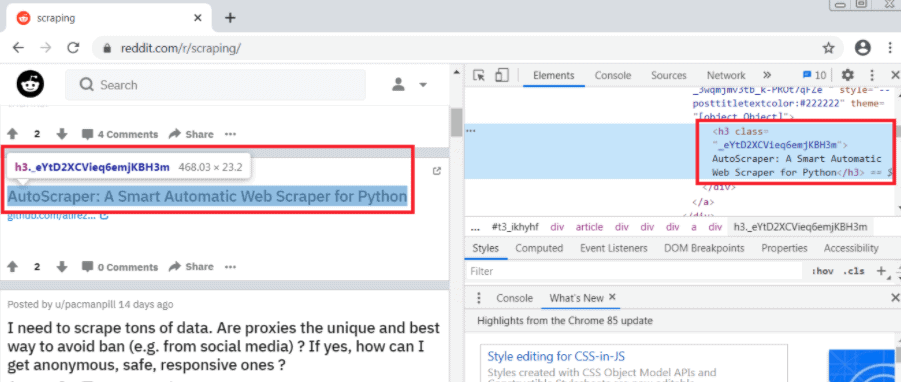
After referencing an HTMLPage, let’s use a CSS selector to find the headings of the posts.
If we use the inspector tool on the Chrome web browser, we see that each post is enclosed in an h3 tag and a _eYtD2XCVieq6emjKBH3m class:
6. Iterating and extracting
Lastly, after selecting the headings, it’s now time to iterate and extract their content.
Here is the code that runs through each heading on the target web page and outputs their content to the console:
for (DomNode content: headings) {
System.out.println(content.asText());
} 7. Adding proxies
Optionally, you can use HtmlUnit to implement a proxy server and evade anti-scraping measures instituted by most popular websites.
To set up a proxy server using HtmlUnit, pass it as an argument in the WebClient constructor:
WebClient webClient = new WebClient(BrowserVersion.CHROME, "myproxyserver", myproxyport));
//set proxy username and password
DefaultCredentialsProvider credentialsProvider = (DefaultCredentialsProvider) webClient.getCredentialsProvider();
credentialsProvider.addCredentials("insert_username", "insert_password");Java Web Scraping – Wrapping up
Here is the entire code for using HtmlUnit for scraping the content of a web page in Java:
Scraping streets names from a map
AutoScraper: A Smart Automatic Web Scraper for Python
I need to scrape tons of data. Are proxies the unique and best way to avoid ban (e.g. from social media) ? If yes, how can I get anonymous, safe, responsive ones ?
How to identify which xhr item is responsible for a particular data?
Telegram scraping
Best Proxies for Web Scraping 2020
Best Proxies for Web Scraping 2020
The A-Z of Web Scraping in 2020 [A How-To Guide]It worked!
Conclusion
That’s how to carry out web scraping in Java using either jsoup or HtmlUnit. You can use the tools to extract data from web pages and incorporate them into your applications. In this article, we just scratched the surface of what’s possible with these tools. If you want to create something advanced, you can check their documentation and immerse yourself deeply into them. This tutorial is only for demonstration purposes.