

Web scraping is the automated process of retrieving data from websites. Many programming/scripting languages offer various tools and options for web scraping. Among them, Ruby offers numerous ready-made tools that can be used in web scraping. In this article, you will learn about Ruby’s two most popular software tools for web scraping and their implementation. You will also get to know how to create your own custom tool for web scraping with Ruby by following this tutorial.
Ruby web scraping frameworks and libraries
Nokogiri
Nokogiri is an open-source software library that is designed as an HTML and XML parser in Ruby. It uses either CSS selectors or XPath selectors to parse data. It is a Ruby gem with a high number of downloads.
Kimurai
Kimurai is a modern web scraping framework in Ruby which works with headless browsers, phantomJS, and many more. This framework allows users to scrape and interact with javascript rendered websites. It is based on the Nokogiri and Capybara gems.
Web scraper vs. parser
Parser – A parser gets the HTML code and extracts the relevant information as text. It produces a structure in memory that the computer can understand and work with. This is a subprocess of the whole scraping process.
Scraper – A scraper extracts data from a website in an automated manner. This process consists of the following subprocesses.
- Make requests and get the response – Process of requesting data from a webpage and receiving the requested data in HTML format.
- Parse and extract – As discussed previously, this is the process of extracting data and saving them in a memory structure.
- Download – Downloading and saving the extracted data in CSV or JSON file formats or in a database.
Building a web scraper with Nokogiri
In this section, let’s discuss how to build a web scraper using Ruby’s Nokogiri library. Here, you will be guided on the complete process, from setting up the environment to creating a CSV file using the scraped data from the webpage.
For this tutorial, We will be scraping a web page from Nike’s official website, which consists of men’s’ ‘Nike by You’ lifestyle custom shoes. There is a title, subtitle, and a price for each shoe listed on this page. We will scrape those data and write them into a CSV file.
Getting Started
Before you begin, make sure that you have fulfilled the following prerequisites.
- Install and set up the rbenv tool.
- Install and set up the latest version of Ruby using rbenv
NOTE: rbenv helps to manage multiple versions of Ruby. Even if you have already installed a version of Ruby in your system, it is recommended to install and set up the latest version using rbenv to avoid conflicts.
First, create a new folder for this project and create a Ruby file and a CSV file inside that folder. You can name those files with any name. In this example, they will be called scraper.rb and data.csv. Now, open the newly created Ruby file (scraper.rb) and download and install the following libraries as gems. Open the built-in terminal of your text editor and execute the following command.
- Nokogiri – A gem that is used to parse HTML data of the scraper. Use the following command to download and install Nokogiri.
gem install nokogiri- HTTParty – A gem that is used to send HTTP requests to the web page which you are trying to scrape. Download and install HTTParty by executing the following command.
gem install httparty Now include the following lines in the Ruby file to use the Nokogiri and HTTParty libraries in your code.
require "Nokogiri"
require "httparty"Then, send an HTTP request to the page which you are going to scrape. In order to do that, You have to create a class named Scraper and pass the URL of the webpage to HTTParty.get() method. The URL of our webpage is “https://www.nike.com/w/mens-nike-by-you-lifestyle-shoes-13jrmz6ealhznik1zy7ok“
class Scraper
page = HTTParty.get("https://www.nike.com/w/mens-nike-by-you-lifestyle-shoes-13jrmz6ealhznik1zy7ok")
endNow, you will be using Nokogiri, which will wrap the page content assigned to the page variable into a special Nokogiri data object by getting in the page variable as a parameter to the Nokogiri::HTML() construct. Then, it will be assigned to an instance variable named @parse_page.
@parse_page ||= Nokogiri::HTML(page)Let’s create a method named initialize and type the above lines of code inside that method. You will be adding a parse_page instance variable there as an accessor.
attr_accessor :parse_page
def initialize
page = HTTParty.get("https://www.nike.com/w/mens-nike-by-you-lifestyle-shoes-13jrmz6ealhznik1zy7ok")
@parse_page ||= Nokogiri::HTML(page)
endBuilding a Parser
We will be using CSS selectors to refer to the data items which need to be scrapped. Now visit the web page and inspect to identify the CSS selectors of the required data items.
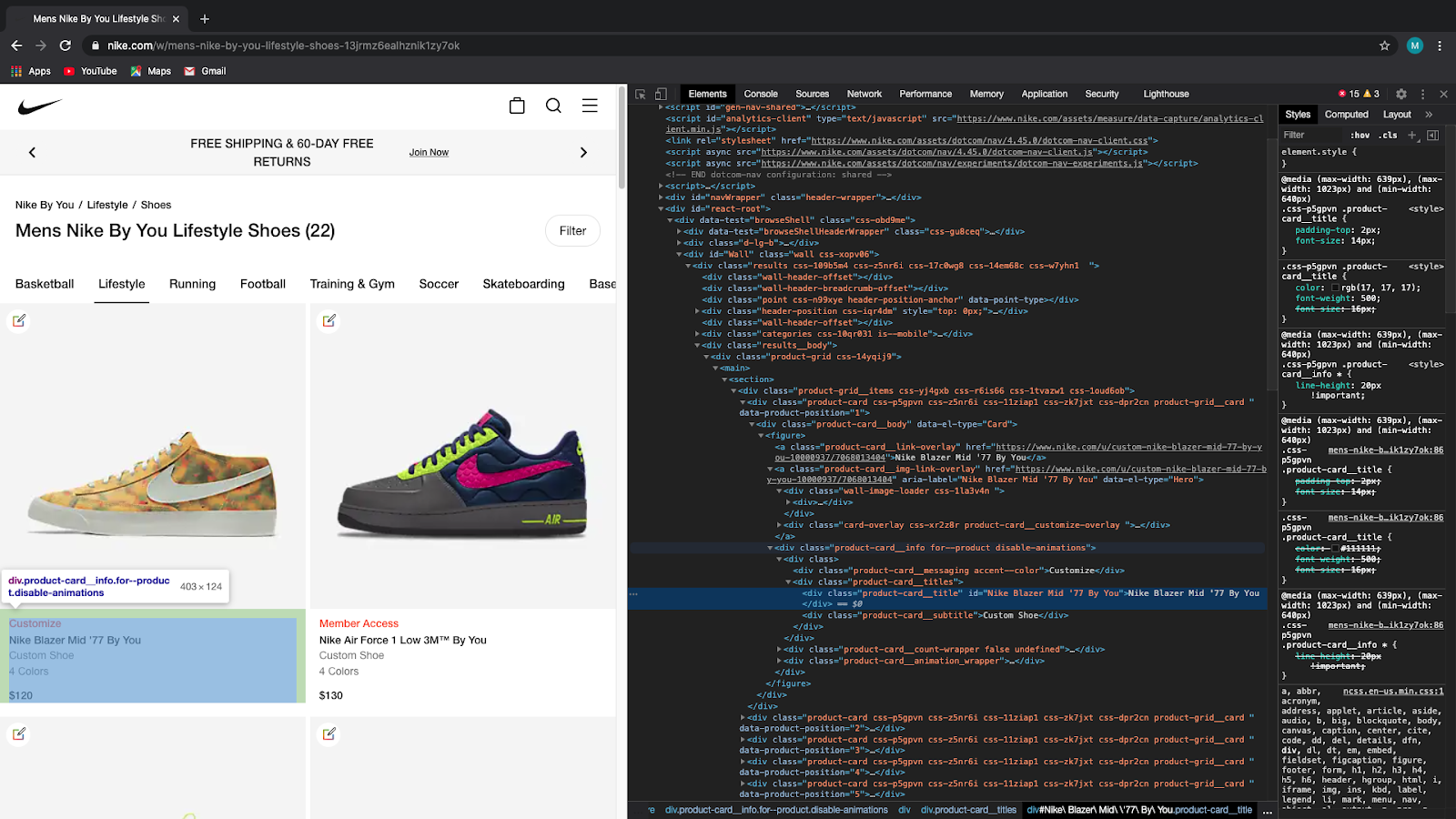
The data items to be scraped out from the web page refers to the following CSS selectors.
Title – .product-card__title
Subtitle – .product-card__subtitle
Price – .product-price
Container carrying these three elements – .product-card__info
You will use the above CSS selectors to scrape the relevant data items by passing them to the Nokogiri’s document object’s css() method. Select the container (div.product-card__info), which includes the data elements by calling the css() method to the instance variable named parse_page, which was created earlier by assigning the data object containing the web page. You can then extract the data elements from all of the containers(div.product-card__info) as text using the text() method. This functionality is achieved through the following code. The data will be assigned to title, subtitle, and price variables.
@parse_page.css('div.product-card__info').each do |char_element|
title = char_element.css("div.product-card__title").text.gsub(/\n/, "")
subtitle = char_element.css("div.product-card__subtitle").text.gsub(/\n/, "")
price = char_element.css("div.product-price").text.gsub(/\n/, "")
end
Then, a new array named shoe_details will be created with the values of those three variables. Next, the shoe_details array, which contains a complete record of a particular shoe, will be included in a new array after checking whether it’s already available in the array.
shoe_details = [title, subtitle, price]
@@shoes << shoe_details if !@@shoes.include?(shoe_details)Finally, you can write these arrays of data into a CSV file using the following code snippet. Make sure to check the name of the CSV file you created earlier and update its name there.
CSV.open('data.csv', "w+") do |csv|
@@shoes.each { |element| csv.puts(element) }
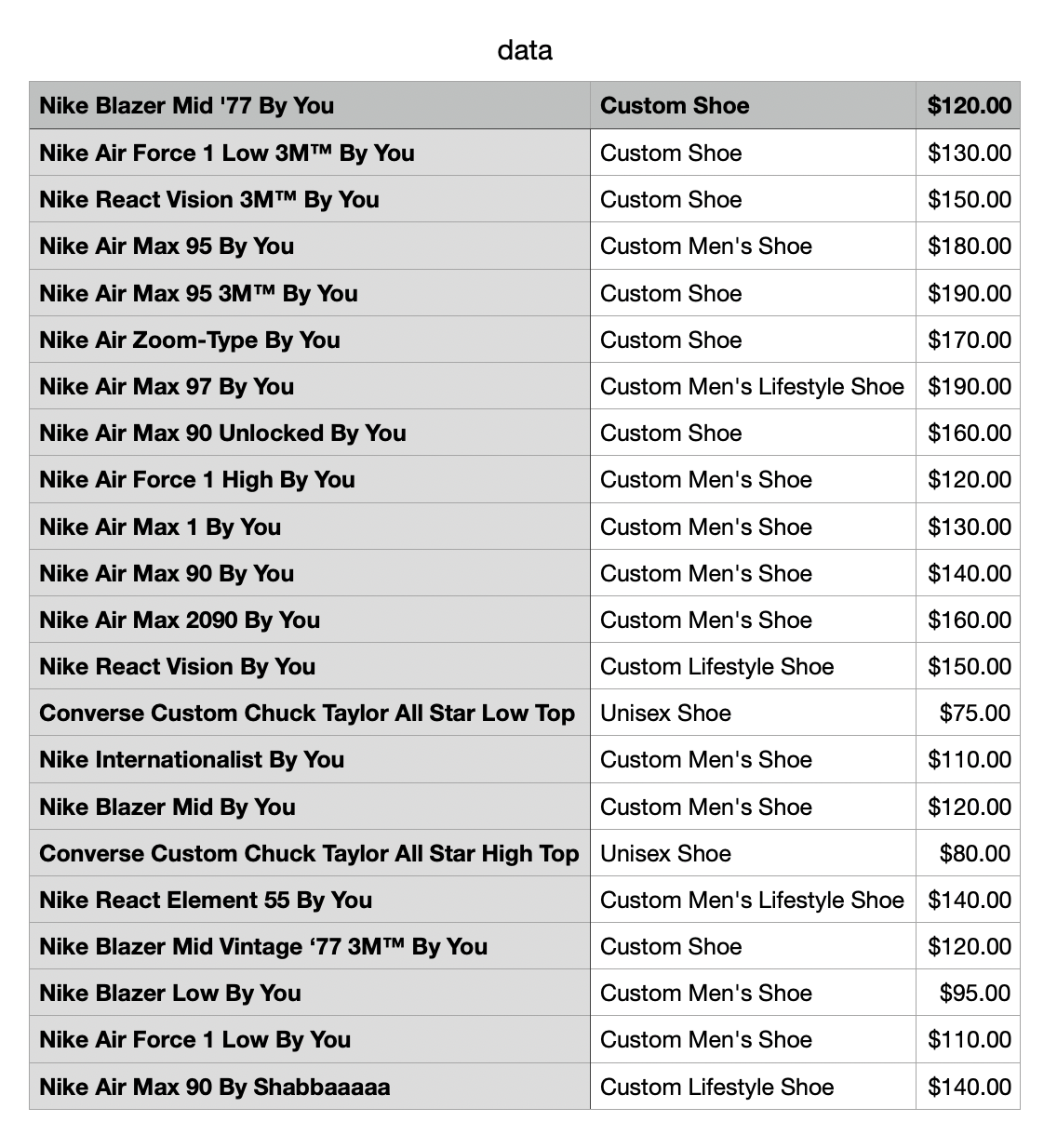
endThe data will be successfully written into the CSV file, as shown below.
Complete Code Snippet
Here is the complete code we created.
Finally, you have successfully scraped a web page using the Nokogiri library and stored the data in a CSV file.
Building a web scraper with Kimurai
This section will guide you on building a web scraper using the Kimurai framework by following a similar approach as we discussed with Nokogiri. However, this time we will scrape data from a different web page.
The web page contains job listings of accountants in Washington, DC, from indeed.com. There are several data elements related to each job posting. So let’s scrape the title, company, location, and salary and create a CSV file with scraped data.
Let’s start with installing Kimurai. You have to execute the following command to download and install Kimurai easily as a gem.
gem install kimuraiNow, create a directory in your file system and create a Ruby file and a CSV file. Name the files as Job_Scraper.rb and jobData.csv. Open the Job_Scraper.rb file in your text editor.
First, call Kimurai library in your code.
require 'kimurai'Then create a class named Job_Scraper and configure it as shown below.
class Job_Scraper < Kimurai::Base
@name= 'acc_job_scraper'
@start_urls = ["https://www.indeed.com/jobs?q=accountant&l=Washington%2C+DC"]
@engine = :mechanize
end
As shown in the code block above, you need to configure and set values to @name, @start_urls, and @engine variables. The purpose of each of these variables is listed below.
- You can set a name for your scraper with @name variable. Name it as you wish or omit it if your scraper uses a single file. In this example, we name our scraper as “acc_job_scraper”
- You can set an array of URLs that need to be scraped for the @start_urls variable. These URLs will be passed to the parse method as an argument. There, add the URL of the web page you are going to scrape.
- @engine variable defines the engine which is used for scraping. You have set it to “mechanize”.
After that, you need to define an array to store the scraped jobs.
@@jobs = []Building a Parser
Define a method named parse inside the class created above, as shown below. The parse method is the start method of the scraper by default.
def parse(response, url:, data: {})
endAs you can see, the parse method accepts several arguments. The response parameter takes a Nokogiri::HTML data object, and the URL parameter takes an array of URLs. The storage for the passing data refers to the data argument. The scraped jobs are stored in an array.
Here, we will use CSS selectors to identify the data elements that need to be scraped and parse the response. Now let’s have a closer look at the web page to inspect and identify the relevant CSS selectors.

As you can see, all the job postings related to the search are grouped in a td element with the id of ‘resultscol’. Inside that td, there are div elements with the class ‘jobsearch-SerpJobCard’. These div elements contain the data elements that you need to scrape.
The following code creates the scrape_job_details method and creates a browser object inside that method. You can scrape the title, company, location, and salary data elements by iterating through all the div elements and store them in a separate array named job_details. Next, we store those data in the @@jobs array.
In the end, call the scrape_job_details method inside the parse method and write the @@jobs array to a CSV file.
Storing in .csv-file
def parse(response, url:, data: {})
scrape_job_details
CSV.open('jobData.csv', "w") do |csv|
@@jobs.each { |element| csv.puts(element) }
end
@@jobs
end
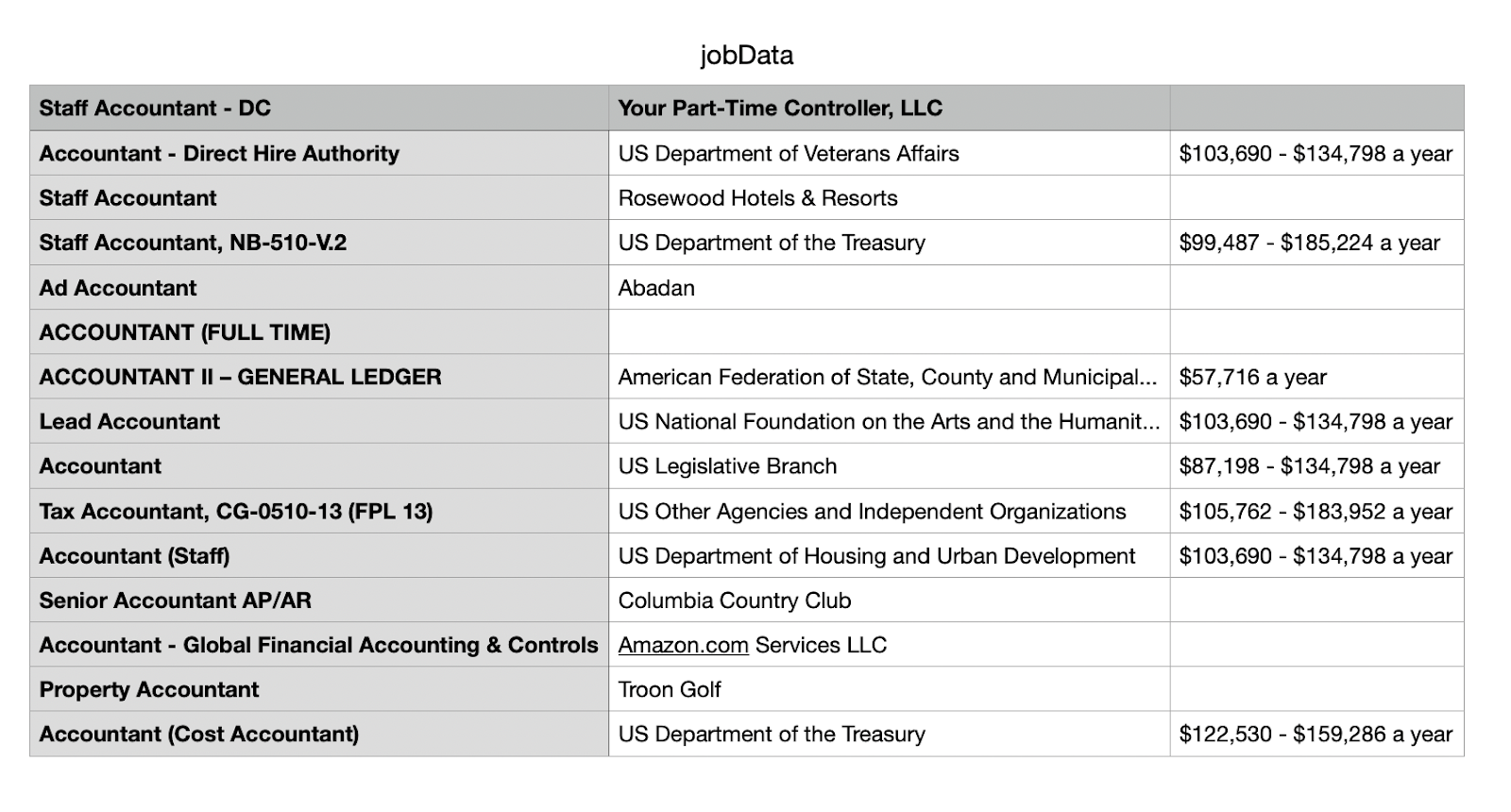
You will get the CSV file with scraped data, as shown below.
Complete Scraper
The complete code should be similar to the following code block.
Conclusion
Now, you have successfully scraped a web page using Kimurai framework and stored the data in a CSV file. I hope you enjoyed our lengthy web scraping with ruby tutorial and see you with the next one.
In case you are planning a larger web scraping project, make sure to check out our web scraping API that handles a lot of issues that occur with larger and ongoing projects.