

Even though it is said that data is readily available on the internet, most of the time users have minimal privileges over this data. That is because the owner of that data has not provided a formal web API or downloadable format for data access. It is neither an effective nor efficient way to extract these data manually as they are in an unstructured format. That is where web scraping comes into play to overcome these limitations. It is a practical and more convenient approach than the manual process. Data and information are crucial for many things such as market research, competitor analysis, price intelligence, etc. In this tutorial, we are going to discuss, how web scraping with PHP can be used to extract data from a website.
Why should we use PHP for web scraping?
PHP is the most widely used server-side programming language. Scraping with PHP is quite convenient as the process has been enhanced using numerous extra tools and libraries. In this tutorial, we will explore some of those PHP libraries and tools. Also, if PHP is the only language you are comfortable with, you have to do it with PHP. It’s not wise to learn a new programming language just for scraping.
Using PHP for data extraction is also recommended when the application which will use the extracted data from web scraping, has also been written in PHP. It will be hard to use a PHP web scraper along with a web application written in some other language like Python. Therefore, in such scenarios, using PHP will be more advantageous.
Ultimately, the most important advantage of using PHP for the job is its ability to automate the whole web scraping process using CRON-jobs. A Cron-job is a software utility that acts as a time-based job scheduler.
PHP web scraping libraries and tools
As described previously, there are plenty of tools and libraries available for PHP. In general, these libraries can be categorized into two types. They are,
- PHP web scraping libraries
- PHP web request libraries
Both these libraries can make requests with all the major HTTP methods and fetch the basic HTML of a web page. One key difference between these two types of libraries is that the web request library doesn’t help parse the web page which your HTTP request returns. Another difference is that web request libraries do not allow you to make a series of requests in order while shifting through a series of web pages you are trying to scrape.
Now let’s have a look at some of these tools and libraries which belong to both types.
Simple HTML DOM parser
HTML Dom parser lets you manipulate HTML easily by allowing you to find HTML elements using selectors. You can scrape information from a web page by just using a single line with an HTML DOM parser. Yet, it is quite slower than some other libraries.
cURL
cURL, which stands for “Client for URLs”, is a built-in PHP component, which is also known as a popular PHP web request library. This library is used for web scraping with the help of strings and regular expressions.
Goutte
Goutte is a PHP library that is based on the Symfony framework. It provides APIs to crawl websites and scrape the contents using HTML/XML responses.
Guzzle
This is another popular PHP web request library that allows you to send HTTP requests easily. It provides an intuitive API, extensive error handling, and the possibility of integrating with middleware.
How to build a web scraper with PHP?
Building a web scraper using a simple HTML DOM parser
This section will guide you through the process of building a web scraper using a simple HTML DOM parser.
First, download the latest version of the simple HTML DOM parser by clicking here. Unzip or extract the downloaded file once the download is complete.
After that, create a new directory and copy and paste the simple_html_dom.php file into the newly-created directory. Next, create a new file with the name scraper.php and save it inside the same directory you created.
Then, open the scraper.php file in your preferred text editor and include the reference to the simple HTML DOM parser library at the beginning of your script. This will give you access to all the functions in the library. You can use the following lines of code to add the reference.
<?php
require_once ‘simple_html_dom.php’;
?>In this example, you will be scraping the web to extract the user reviews of the movie “Guardians of the galaxy” from IMDB.com. The link to the target Web page is, https://www.imdb.com/title/tt2015381/reviews?ref_=tt_urv .
Building the Scraper
First, you need to create a DOM object to store the content of the above URL. You have to create a variable called HTML and assign it the value which returns as the DOM object from the file_get_html_() function. For that, include the following line of code in your script. We will optimize the fetching part further down in this tutorial.
$html = file_get_html(‘https://www.imdb.com/title/tt2015381/reviews?ref_=tt_urv‘, false);Here, you will be extracting the number of star ratings, the title of the review, and the review content from that web page.

To scrape these data, you need to identify the HTML elements and CSS selectors which refers to them. It can be done by inspecting the web page in your browser.
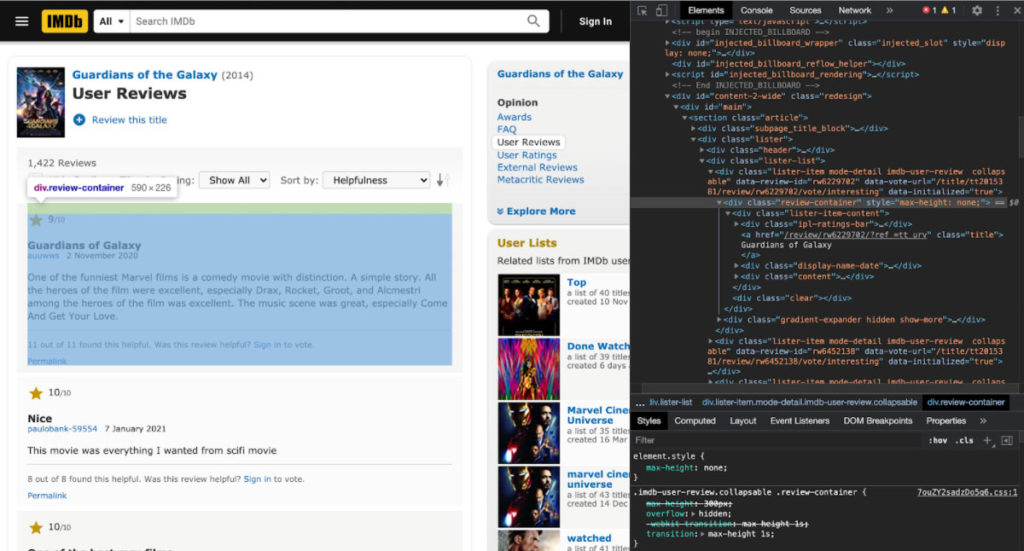
As you can see, there is an HTML div element with a CSS class selector named review-container, which contains all the data fields that are required.
You can use a for-each loop to extract the above-mentioned data from all the user reviews with the help of that class selector. Inside the review container, the following class selectors refer to the required data as listed below.
- Ipl-ratings-bar refers to the number of star ratings.
- The title refers to the title of the review
- Text show-more__control refers to the content of the review
You can use the for-each loop for the above three CSS selectors as well. To do that, include the following lines of code in your script.
Complete Code Snippet
Now, all the extracted data have been stored in an array named $results. If you print that array, it will give an output similar to the following screenshot.
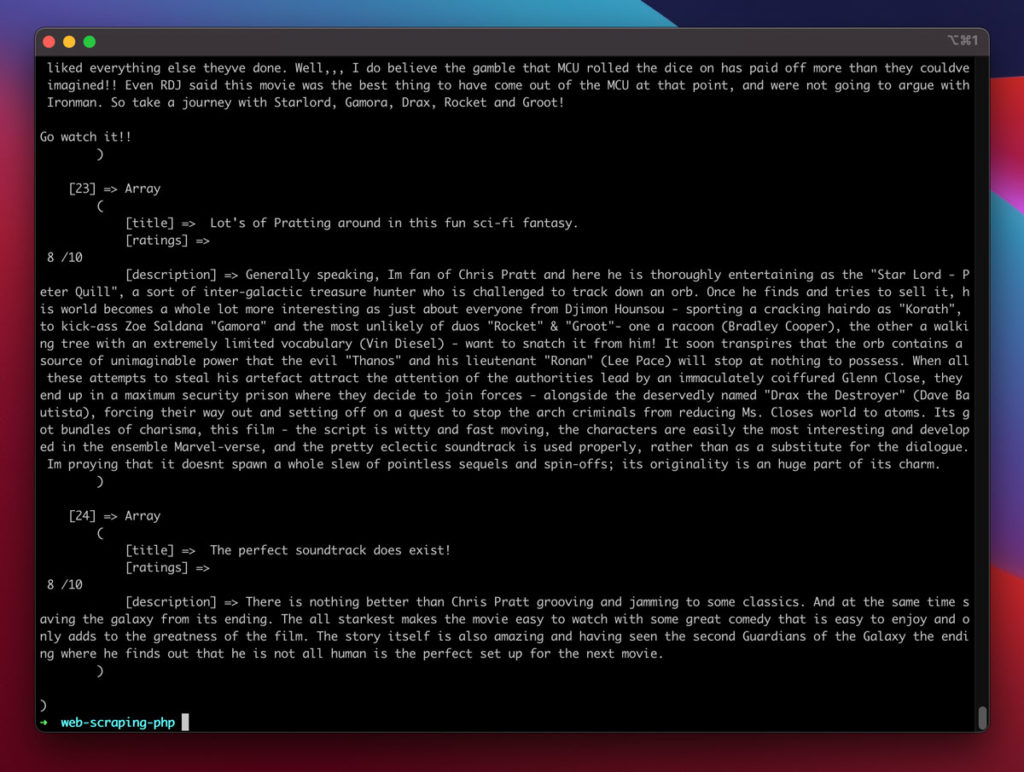
Then you can store the scraping output in an XML file. For that, first, you need to convert the $results array into an XML element. There is a built-in class named SimpleXML Element which can be used in that process. The following blocks of code will do that.
Now the data is stored in $xml_content variable. So you need to create an XML file and write the data in that variable to that XML file. Add the following lines of code to generate an XML file and write data to it.
Finally, the job is completed, using the simple HTML DOM parser. All the data is stored in an XML file.
Building a web scraper using Goutte and Guzzle
This section will explain how to build a web scraper using Guzzle and Goutte libraries, which were discussed earlier in this tutorial. To use Goutte, you must have PHP 5.5 or a higher version and Guzzle 6 or a higher version installed on your PC. Technically Goutte is a wrapper that is wrapped around Symphony components like DomCrawler, BrowserKit, CssSelector, and the Guzzle HTTP client component. As a prerequisite for installing Goutte, you need to download and install Composer which is the package manager for PHP.
Installing Composer
Click here to download the composer.
Once the Composer is installed, you need to install Goutte using composer. Execute the following command to download and install Guzzle first as Goutte depends on Guzzle.
composer require guzzlehttp/guzzleThen, you need to install Goutte using the following command.
composer require fabpot/goutteNext, you have to install one more library named Masterminds. Use the following command to install Masterminds.
composer require masterminds/html5After installing the above three libraries, the dependencies will be automatically updated in the composer.json file. It should be similar to the following code snippet.
{
"require": {
"guzzlehttp/guzzle": "^7.2",
"fabpot/goutte": "^4.0",
"masterminds/html5": "^2.7"
}
}Building the Scraper
Once the installation is completed, create a new file named Goutte_scraper.php. Then enable Autoload which will load all the files that are required for your project/application. Add the following line of code at the beginning of your script to enable Autoload.
require 'vendor/autoload.php';Now you need to create an instance of the Goutte client. Run the following code to create a Goutte client instance named $client.
$client = new \Goutte\Client();After that, you can make the HTTP requests with a request() method as shown below. The request() method returns a crawler object. You will be using the same website which was used for scraping with a simple HTML DOM parser. But this time you will be scraping only the title of the review.
URL of the web page is, https://www.imdb.com/title/tt2015381/reviews?ref=tt_urv and the CSS class selector of the review title which you are going to extract is the title.
First, you need to get the web page using HTTP GET request. For that, include the following code in the script.
$crawler = $client->request('GET', 'https://www.imdb.com/title/tt2015381/reviews?ref_=tt_urv');Then, use the following lines of code to extract the review title.
$results = [];
$results = $crawler->filter('.title')->each(function ($node) use ($results) {
array_push($results, $node->text());
return $results;
});The complete script should be similar to the following snippet of code.
The above script will generate an output similar to the following snapshot.
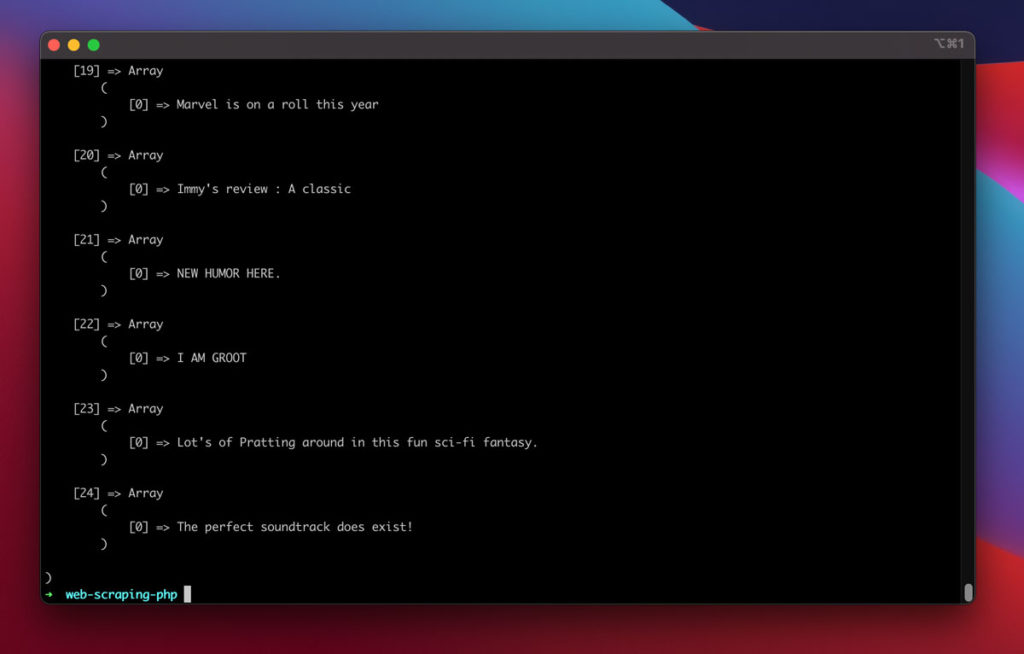
In the end, you have successfully implemented a web scraper using Goutte and Guzzle libraries.
Conclusion
Web scraping is a popular aspect of backend development. PHP has enormous support for tools and libraries used for data extraction as one of the best backend development languages. It is difficult to point out which one is the best among those tools and libraries as each of them has its own use cases, advantages, and disadvantages. Therefore, you should be careful when choosing the right tool or library for scraping as it depends on your requirements.
Also, check out our other web scraping tutorials.