

Web scraping is the automated process of collecting data and information from websites. Many Programming/scripting languages provide various solutions for web scraping. R is a popular programming language for web scraping. In this tutorial, you will be guided through the process of web scraping using the R programming language. There, a popular R package named rvest will be used for web scraping. You will be able to discover advanced functionality related to R web scraping, such as scraping nested links and multiple pages with the help of the rvest package by referring to this article.
Pre-requisites
- First, you need to download and install R from the CRAN downloads page.
- Then, download and install RStudio, which is the Integrated Development Environment for R.
- After that, you have to download Selector Gadget and add it as an extension to your browser. Navigate to selectorgadget.com and follow the instructions there to add it as an extension. Once it is added, pin it to the extensions bar as shown below.

Scraping a web page using ‘rvest’
In this tutorial, you will be scraping data from the IMDb website using the rvest package. The web page we will scrape consists of data related to the movies, released in 2020 and sorted by popularity. You have to scrape the following data related to each movie from that web page.
- Name of the movie
- Released year
- The runtime of the movie in minutes
- The genre of the movie
- Synopsis of the movie
- Rating
- The number of votes acquired.
To begin, create a new directory in your file system. Then create a script file inside that directory using the RStudio IDE.
First, you need to install two required packages, namely rvest, and dplyr. Among these two packages, rvest is mandatory, as it is the R web scraping tool that will be used in this tutorial. The dplyr package is optional, yet will be very useful as it provides a cool feature called piping, which makes things easier. Run the following lines of code in the console to install those packages.
- To install the rvest package,
install.packages('rvest')
- To install the dplyr package
install.packages('dplyr')
Next, load the two libraries which you have just installed by executing the following lines of code.
library(rvest)
library(dplyr)
Then, assign the URL of the web page to a variable named link and get the page’s HTML content by passing that variable to the read _html() function. After that, assign the retrieved HTML content of the page to a new variable named page, as shown below.
link = "https://www.imdb.com/search/title/?year=2020&title_type=feature
page = read_html(link)
Building a Parser
The next task is to identify the CSS selectors of the HTML elements you want to scrape. You can use the Selector Gadget chrome extension for this process.
For that, open the web page to be scraped and click on the Selector Gadget extension icon in the extensions bar of the browser. It will prompt an interface that will display the corresponding CSS selector when you click on the web page’s HTML element.
First, let’s scrape the names of the movies. Click on the Selector gadget and then click on the name of a movie. Many elements, including the name field, will be highlighted as shown below.
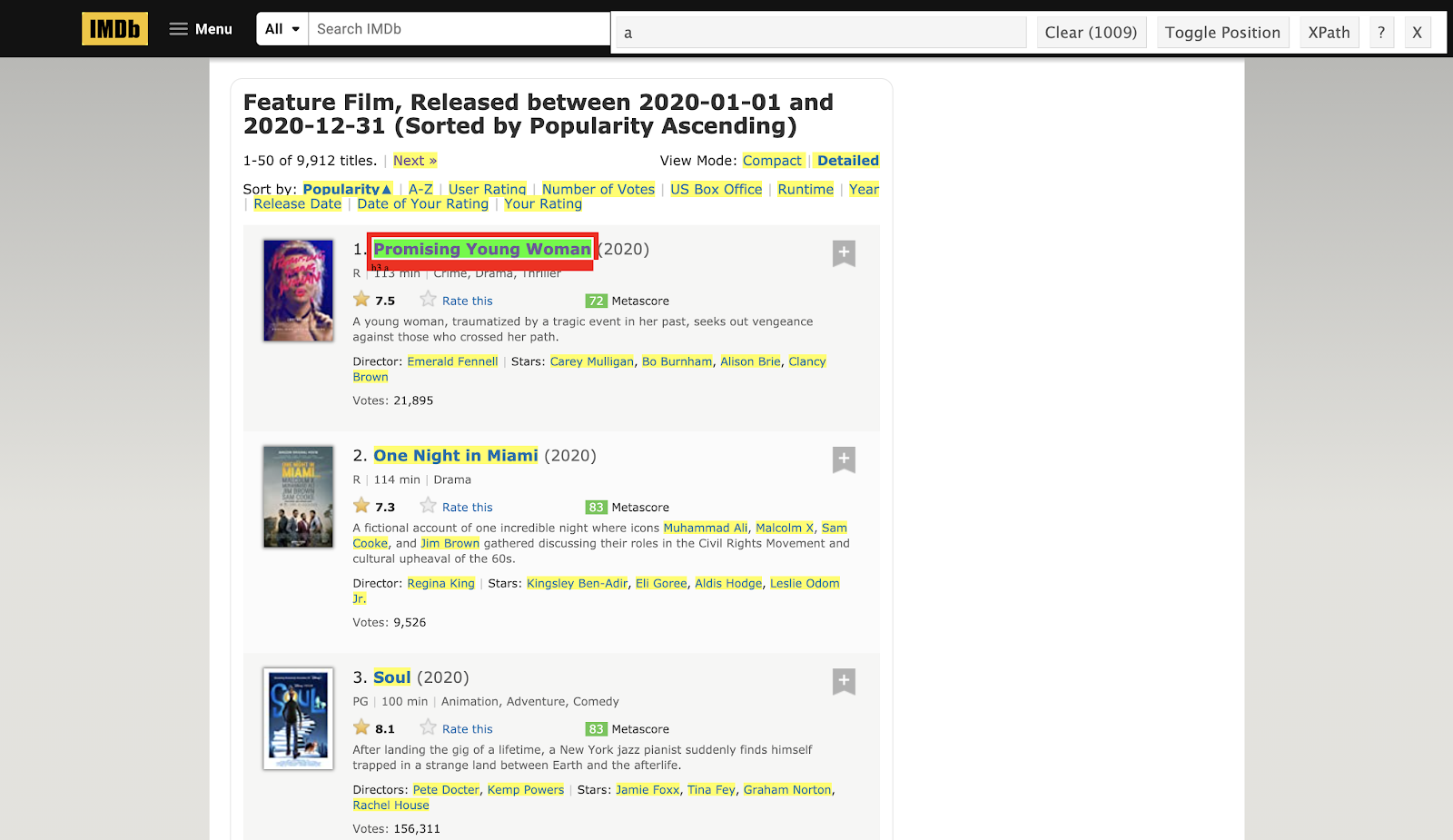
However, you just need the name field. You can deselect the rest of the fields by re-clicking on those unnecessary elements. Once you click on an unnecessary element, it will get highlighted in red, as shown below, and the exact CSS selector of the name field will be displayed on the Selector Gadget window.

Now you have got the corresponding CSS selector for the name field, which is .lister-item-header a.
Then, let’s see how to use the name. html_nodes() function to extract the data which is relevant to the CSS selector from the web page. The page variable which contains the HTML content of the web page and the specific CSS selector should be passed into the html_nodes() function. Then, the html_text() function will extract the text form of the selected nodes. This could be done as shown below.
name_data_html = html_nodes(page, '.lister-item-header a')
name = html_text(name_data_html)But with the dplyr package, you can do this with a single line of code using, dplyr pipes, as shown below. The pipe operator %>% passes the processed data on the left side of the operator to the function, which is on the right side of it as the first argument.
name = page %>% html_nodes(".lister-item-header a") %>% html_text()You can see the output of the above code line by just calling the name variable in the console after running it.

Now you have successfully scraped the movie names from the web page. So you can continue to scrape the rest of the data elements as shown below.
year = page %>% html_nodes(".text-muted.unbold") %>% html_text()
runtime = page %>% html_nodes(".runtime") %>% html_text()
genre = page %>% html_nodes(".genre") %>% html_text()
synopsis = page %>% html_nodes(".ratings-bar+ .text-muted") %>% html_text()
rating = page %>% html_nodes(".ratings-imdb-rating strong") %>% html_text()
votes = page %>% html_nodes(".sort-num_votes-visible span:nth-child(2)") %>% html_text()You can check the data frame by executing View(movie_list) on the console. The data frame should be something similar to the following output.

Now, you can go ahead and write this data frame into a CSV file. Before that, you need to specify the working directory to the location of the source file, which is the directory you created earlier. To do that, navigate to Session >> Set Working Directory >> To Source File Location.

Then, you can generate a CSV file and write the data frame to it using the following line of code.
write.csv(movie_list, "Feature Films(2020-01-01 and 2020-12-31).csv")The above code will generate a CSV file in your directory as follows.
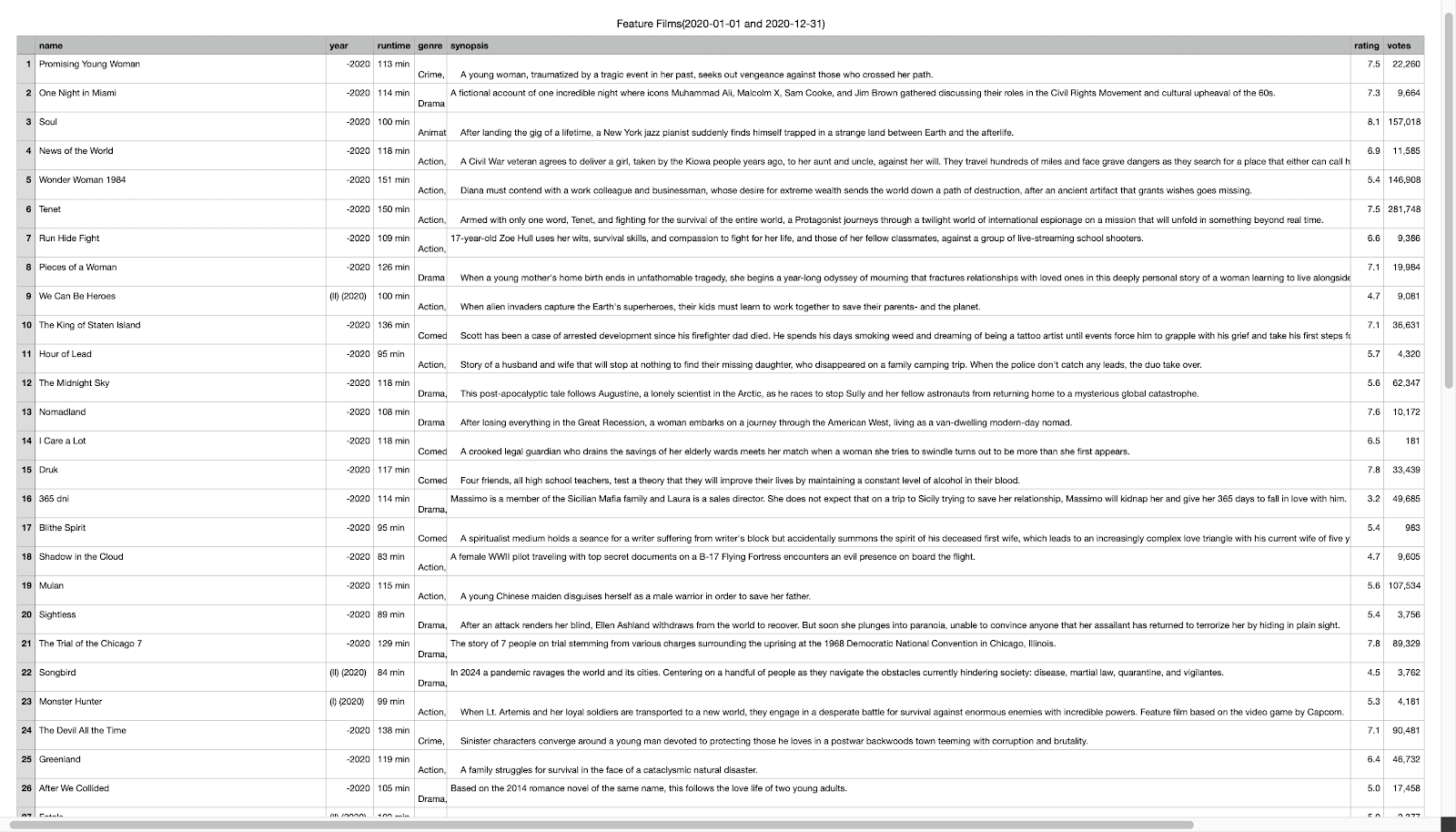
Finally, you have successfully built a web scraper in R using rvest package. Now, let’s see how to extend the functionality of our R web scraper.
How to scrape data from nested links?
Nested links are clickable links in a web page, which you can use to navigate to other web pages. While scraping the web, there might be a situation where you need to scrape a detail of a product or an item that is not available on the current page but is available on the product/item page. So you need to navigate that product page by clicking the product link to scrape that data. Let’s see how to implement this functionality within this section.
In the previous section, you scraped all the required data from that web page itself, and now you have to scrape the cast overview of each movie. That data is available on each movie page, which has separate links.

Let’s modify our code to add these data to the data frame you have already created as a new column.
First, you need to grab the URLs of each movie page. Remember that you used the function html_nodes() to scrape movie names using CSS selectors. Let’s check the output that the function produces by executing the following code in the console.
page %>% html_nodes(".lister-item-header a")You will get an output similar to the following.

You can notice that there are URLs of movie pages and the highlighted part of the above output is the URL of a movie page, as shown below.

As you can see, the URL of a movie page consists of two parts.
- The first part is the URL of the web page, and it remains the same on all the movie pages.
- The second part is generated for each movie by the html_nodes() function and the CSS selector of the movie name.
Now, you need to combine these two parts and build the complete URL for each movie page. This can be done by using the following line of code. There, you will pipe the value generated by the html_nodes() function into html_attr() and pass href to it as an argument. Then you have to use the paste() function to concatenate these two parts. In the end, the complete movie links will be saved in a variable named ‘movie_links’. Include the following line of code under the name scraping line to achieve this functionality.
movie_links = page %>% html_nodes(".lister-item-header a") %>% html_attr("href") %>% paste("https://www.imdb.com", ., sep = "")After executing the above code, you can check the movie links by executing the ‘movie_links’ variable in the console, as shown below. You can copy and paste a link there in your browser to check whether it is working.

Now, you have retrieved all the URLs of the movie pages. All that is left to do is scrape the cast overview using the relevant CSS selectors by navigating those URLs. This can be done in the same way you did with movie names, and the Selector Gadget will be helpful in identifying the CSS selector of cast members.
The following function will illustrate this functionality.
get_cast = function(movie_link) {
movie_page = read_html(movie_link)
movie_cast = movie_page %>% html_nodes(".primary_photo+ td a") %>% html_text() %>% paste(collapse = ",")
return(movie_cast)
}
This function returns all the cast names as a single string.
Now you need to pass all the URLs of movies one by one to this function so as to get the cast members of each movie. You will be using the sapply() function for this. The sapply() the function will get the movie_links and the get_cast function as parameters. It will access each movie URL in the movie_links vector and pass it to the get_cast() function. In the end, the result will be assigned to a variable named cast.
cast = sapply(movie_links, FUN = get_cast, USE.NAMES = FALSE)Finally, you can also add the cast to the data frame. The following code can be used to update the data frame with the cast members.
movie_list = data.frame(name, year, runtime, genre, synopsis, rating, votes, cast, stringsAsFactors = FALSE)
You can see the output of the updated data frame as shown below.

Now, you know how to scrape data from nested links in R using rvest. So let’s move on to see how to scrape data from multiple pages.
How to scrape data from multiple web pages?
By now, you are familiar with R web scraping data on a single page and from nested links. So it’s time to scrape data from multiple pages. Let’s modify our code to achieve that.
You can see that there are more movies on other pages, and one page contains only 50 movies.

The First step is to figure out how the URL is changing when you move from one page to another by clicking Next. Let’s see how it’s getting changed.
URL of the first page

The URL of the second page

and the URL of the third page

As mentioned earlier, one page consists of 50 movies. You can notice that the sections of the second and third page URLs increase by 50. By that, you can figure out how the URL changes when moving to the next page. When you set the start=1, it directs to the first page. You will be using that link as the starting web page and use a for loop to move from page to page.
Let’s create a for loop with a variable called page_result. You can then use the seq() function to increase the page_result by 50, whereas the starting value of 1 to 51. We need to set 51 as the maximum number as you will be scraping only the first two pages. You can increase it as you want (3 pages = 101, 4 pages =151, 5 pages = 201, etc.).
for (page_result in seq(from = 1, to = 51, by = 50)){
}Now you need to update the URLs starting with the page_result. You can use the paste() method to concatenate the link with the page_result variable, as shown below.
Note: The paste0() the method will be used to avoid keeping space in between the URL.
link = paste0("https://www.imdb.com/search/title/?title_type=feature&year=2020-01-01,2020-12-31&start=", page_result , "&ref_=adv_nxt")Complete Guide Snippet
The complete code for the R web scraper can be arranged as shown below.
Note: rbind() the function has been used to add new rows to the existing data frame while avoiding replacing them.
Finally, you have successfully built a web scraper in R using rvest package, which can scrape nested links as well as multiple web pages.