

If your work revolves around gathering massive amounts of data from the web, a web scrape API should be a must-have in your life. You can automate web data extraction from different web pages with the help of web scraping API and Python libraries. This can save hours of manual labor. Not to mention, whether the data is organized or not, web scraping enables you to extract it from any web page. In this article, we’ll look at the potential of web scraping with Python libraries.
What Is Python Web Scraping?

Python web scraping is the practice of using a Python script to autonomously gather information from websites. This includes parsing a website’s HTML or XML, extracting the necessary information, and storing it in a structured file like a JSON, CSV file, or SQL database. Scraping is useful for many different purposes. This includes data mining, price tracking, sentiment analysis, and content aggregation.
Why Python Is Suitable for Web Scraping?
Python is a popular programming language for web scrape activities because of its extensive library, simplicity, and adaptability. Parsing HTML, interacting with websites, and extracting all the data is made simple with a python web scraper. This is because of the Python libraries like Beautiful Soup, Selenium, and Requests. Besides, Python is a great option for the web scrape process because of its clear and readable syntax. This enables fast and effective coding. Python is also common for web scraping due to its compatibility with a number of operating systems, including Windows, Linux, and macOS.
If you want to get started with Python web scraping, check out our quick guide on getting started with python web scraping.
What Are the Popular Python Libraries for Web Scraping?

Web scraping has become an increasingly popular technique to extract information from websites. Python comes with a number of tools that streamline and improve the web scrape process. The e-commerce, finance, marketing, and research sectors all frequently use the following libraries:
Selenium
Python’s Selenium library automates web browsers. It enables users to manipulate popular web browsers like Google Chrome, Firefox, and Safari and mimic actions like clicking, scrolling, and form-filling. Because of this, it’s useful for web scraping tasks that demand user authentication, like gathering information from social media websites.
BeatifulSoup
BeautifulSoup is a Python library that parses HTML and XML documents and extracts data from them. Users can extract data based on tag names, attributes, and text content, and it offers a straightforward interface for navigating and searching the parse tree. It is frequently used to extract data from web pages with poorly structured formats.
Requests
Requests is a Python library that simplifies the process of making HTTP requests and handling responses. When a user submits an HTTP/1.1 request, cookies, headers, and authentication are all taken care of automatically. It’s often used for scraping tasks that call APIs or make requests to websites.
What Are Other Options for Web Scraping?
Web scraping can be done using a variety of techniques, each with benefits and limitations of its own. Scraping techniques that are frequently used include the following.
- Manual scraping: This involves manually visiting a website, copying the necessary publicly available data, and pasting it into a database or spreadsheet. This is very time-consuming and makes it unsuitable for scraping huge amounts of data.
- Browser extensions: They are software programs that extract data from websites and load it onto web browsers like Chrome and Firefox. They are helpful for extracting data from small web pages and frequently use point-and-click user interfaces.
- Web scraping services: Users can extract data from websites without writing any code by using one of the many third-party web scraping services that are accessible. These services frequently have a cost and might have restrictions on how much data can be extracted.
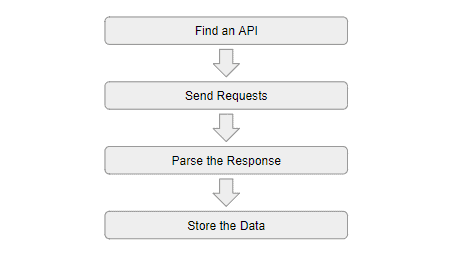
Scraping data from APIs is a popular method for collecting data from websites. Applications can communicate with web-based services in a structured and effective manner using APIs. This frequently returns data in a machine-readable format like JSON or XML. Here’s how scraping data from APIs works:
- Before you can scrape data from an API, you must first locate a website that offers an API. While some websites give public APIs that are free to use, others demand payment or authentication.
- After finding an API, you must make requests to it in order to obtain the data you require from the web servers. You can use the HTTP protocol and a web scraping library like Python’s Requests for this. You must give the API any necessary criteria as well as your authentication information.
- The API will reply with the scraped data in an XML or JSON format that can be read by computers. To get the specific data you need, you must analyze this data. You can use related Python modules for that.
- After you extract the data, you can export data in a structured file, such as a CSV, JSON, or SQL database. This makes the data simpler to evaluate and use in subsequent processing.
Why Should You Use Zenscrape for Web Scraping?
Zenscrape offers a user-friendly, reliable, and efficient way to scrape websites and collect valuable data. With its easy-to-use API, Zenscrape simplifies the web scraping process, allowing developers to focus on the analysis of the data rather than the collection process.
Zenscrape also provides a range of advanced features, including the ability to handle JavaScript code and dynamic content, as well as support for proxies to keep your scraping activities anonymous. Proxies allow developers to use different IP addresses for their scraping requests to avoid detection and blocking by a target website.
Whether you’re scraping e-commerce data or collecting research data, Zenscrape is a powerful tool that can help you get the data you need quickly and efficiently.
Try Zenscrape today and start collecting valuable data for your business or project.
FAQs
What Is a Web Scraping API?
It’s an interface for developers to extract data from websites programmatically.
How Does a Web Scraping API Work?
It returns data in a machine-readable format like JSON or XML when developers send requests to it.
Is It Legal to Use a Web Scraping API?
It depends on the terms and conditions of the website you are scraping.
What Are the Advantages of Using a Web Scraping API?
APIs save time and resources by providing structured and efficient data extraction.