
Performing advanced web scraping is sometimes throttled because of sending too many requests from the same IP address. However, a proxy rotator can assist you in getting around most of the anti-scraping measures, ensuring you extract data successfully. With a proxy service, you can obfuscate your IP address and sidestep any rate limits implemented on the target website.
In this article, we’ll demonstrate how to build a simple IP rotator in Python and take your scraping efforts to the next level.
Proxy rotator – Prerequisites
Here are the resources we’ll be using in this project:
- https://sslproxies.org/ —we’ll grab some free HTTPs proxies from this site. It has several IP addresses and corresponding port numbers that we can set as proxy request calls, ensuring our real IP is hidden from the target’s server. You can also pick a proxy from any other website.
- random—we’ll use this Python library to ensure we get a random choice of proxies. Since it’s part of the Python standard libraries, we’ll simply import it to our project and use its choice function.
- requests—we’ll use this Python library for sending HTTP requests. We’ll also import it to our project. If you do not have the library in your Python environment, you can install it by running this command: pip install requests.
- Beautiful Soup—we’ll use this Python library to extract a free list of proxies from the above-mentioned website. You can install it by running this command: pip install beautifulsoup4.
Here is the code for adding the libraries to the project:
from random import choice
import requests
from bs4 import BeautifulSoup
Now, let’s get our hands dirty!
Scraping a proxy list
Let’s start by creating a script that scrapes free proxies from https://sslproxies.org/ and inserts them into our Python proxy rotator project.
Let’s invoke the requests.get() method to retrieve a list of proxies from the website:
response = requests.get("https://sslproxies.org/") Then, let’s convert the response to a Beautiful Soup object so that we can extract the content more efficiently. We’ll use the html5lib parser library to parse the site’s HTML, just like a browser.
Here is the code:
soup = BeautifulSoup(response.content, 'html5lib') On the sslproxies website, the IP addresses and the port numbers are contained within the HTML <td> tags.
Here is a screenshot of a section of the site’s homepage:
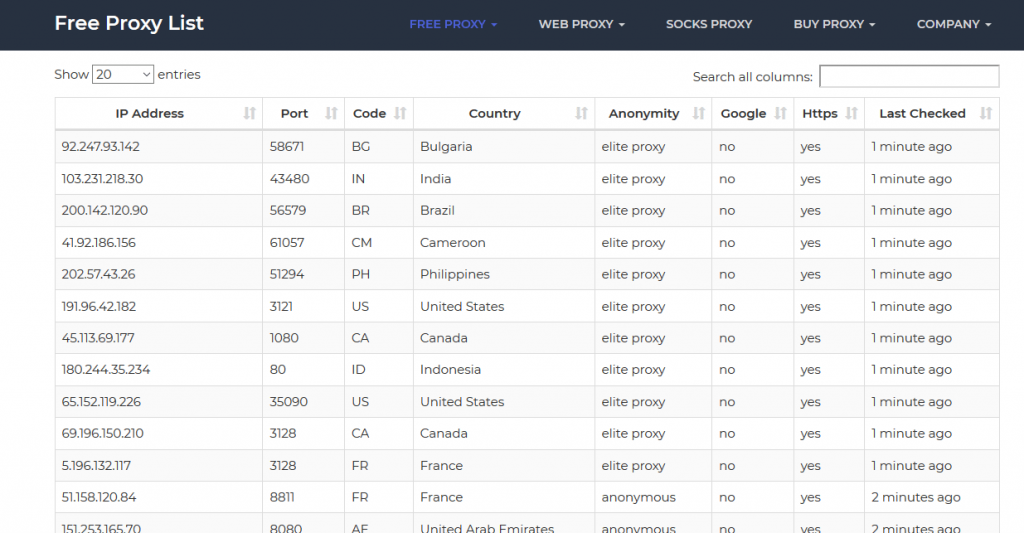
If you check the website carefully, you’ll notice that every eighth column contains an IP address.
So, we can use the Beautiful Soup’s findAll function to extract the IP addresses from the website.
Here is the code:
soup.findAll('td')[::8] If we run the code, here is the result we get (for brevity, we’ve truncated the screenshot):
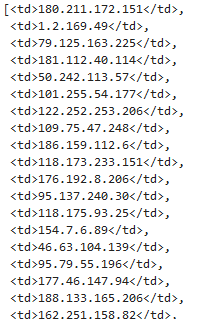
Similarly, here is the code for retrieving the corresponding port numbers:
soup.findAll('td')[1::8] If we run the code, here is the result we get:
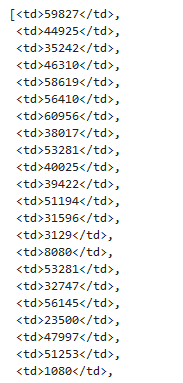
Next, let’s embed a lambda function within the map() function and convert the HTML element into a simple text; for both retrieved IP addresses and port numbers. We’ll also zip them up to get a series of tuples where each tuple represents the extracted IP and its associated port number. We’ll consume the returned data using the list() function.
Here is the code:
list(zip(map(lambda x:x.text, soup.findAll('td')[::8]), map(lambda x:x.text, soup.findAll('td')[1::8]))) If we run the above code, here are the results we get:

Also, let’s add another map() function that converts the tuple into a simple string:
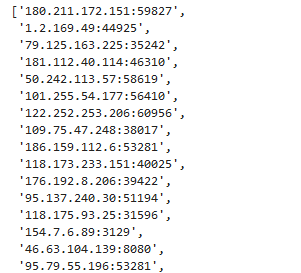
list(map(lambda x:x[0]+':'+x[1], list(zip(map(lambda x:x.text, soup.findAll('td')[::8]),
map(lambda x:x.text, soup.findAll('td')[1::8]))))) If we run the above code, we’ll get a list of the IP addresses available on the sslproxies website.
Randomising the proxy list
Consequently, we’ll use the choice function that iterates over the generated list of proxies and selects one IP address randomly; and without choosing the same proxy two times in a row. Furthermore, we’ll convert the result into a proxy dictionary, according to the stipulations of the request library.
Here is the code:
{'https': choice(list(map(lambda x:x[0]+':'+x[1], list(zip(map(lambda x:x.text, soup.findAll('td')[::8]), map(lambda x:x.text, soup.findAll('td')[1::8]))))))}If we run the above code, we get a randomly chosen IP address:
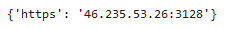
Finally, let’s wrap the entire code for generating random proxies in a function called proxy_generator():
Scraping data using free IP rotators
After knowing how to generate random proxies using a free proxy list rotator, let’s now see how you can use the generated proxies to send HTTP requests and harvest online data successfully.
To achieve this, we’ll create another function called data_scraper(), which takes the following three arguments: the type of HTTP request, the URL to the website to be scraped, and a dictionary of keyword arguments.
We’ll use the while loop statement to send repeated requests to the proxy server until a valid proxy is retrieved; if the request is not successful, the proxy will be rotated again. We’ll also use the try…except statements to handle any errors in our code and raise exceptions if there are any issues.
To generate a random proxy, we’ll call the previously created proxy_generator() function. Then, to verify that we’re using a different IP address for each iteration, we’ll print the proxy that is currently being used.
Lastly, we’ll invoke the requests.request() function and pass the previously stated arguments alongside the generated proxy and timeout (the period to wait before sending another request).
Here is the entire code for the data_scraper() function:
Testing the Python IP rotator
Now, let’s see if we can generate a random proxy and use it to scrape data from this blog post.
Let’s run the following code:
response = data_scraper('get', "https://zenscrape.com/ultimate-list-15-best-services-offering-rotating-proxies/")Here is what is printed on the console:
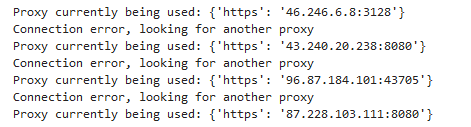
As you can see on the screenshot above, a different IP address is used for each iteration.
To get the HTML content of the response, we can simply run this code:
response.text Here is the screenshot of the output:
It worked!
Here is the whole code for creating the simple Python IP rotator:
That’s how you can build a free proxy list rotator in Python and scrape the content of any website successfully.
5 tips for building a proxy rotator that actually works
Here are five tips you need to keep in mind when rotating proxies using a Python proxy rotator.
1. Desist from using predictable proxy IP addresses
Most anti-scraping tools can detect requests sent automatically from IP addresses that are in a predictable format, such as in a continuous range or belonging to the same group.
For example, using the following rotating IP addresses will quickly raise the red flag:
103.243.132.10
103.243.132.11
103.243.132.12
103.243.132.13
103.243.132.14
2. Combine IP rotation with user agent rotation
While IP rotation allows you to rotate multiple IP addresses and avoid detection, some anti-scraping measures can recognize such activities and block you from harvesting data. Therefore, to increase your chances of success, apart from rotating IP addresses, you also need to rotate user agents. Using random user agents, instead of a single one, will make it appear that your requests are sent from different browsers.
3. Go for reliable free proxy services
Most of the free proxy services available out there are congested, which may lead to frustrating delays and unexpected crashes. Therefore, if going for a free proxy, do some homework and get one that can match your scraping needs without significant drawdowns.
Furthermore, since most free proxies tend to be valid for a limited period, you can build a scraping logic in your Python code that automatically updates the free proxy list rotator with working IP addresses. This way, you’ll avoid disruptions when scraping.
4. Consider a premium proxy service
While free proxy IP rotators can help in getting the job done, they tend to be crowded, slow, and insecure. Therefore, if you are performing advanced, large-scale web scraping tasks, a free proxy rotator may be unsuitable.
With a good premium proxy service, you’ll get a high quality service that ensures you scrap thousands of web pages without experiencing disruptions or blockades. So, you can consider paying a few dollars and get a provider that will guarantee your privacy and sufficiently meet your data extraction needs.
Zenscrape Proxies offers premium residential proxies form a range of over 8.5M IP addresses starting at 65$ / month. Register for free
5. Go for elite proxies
There are three main types of proxies on the Internet: elite proxies, transparent proxies, and anonymous proxies. Out of these, elite proxies offer the best option for bypassing restrictions and avoiding detections. With an elite proxy, you can only send REMOTE_ADDR header while keeping the other headers empty, resulting in optimal privacy.
On the other hand, a transparent proxy sends your real IP via the HTTP_X_FORWARDED_FOR header as well as via the HTTP_VIA header, which gives away the details of your IP address. An anonymous proxy does not disclose your real IP address; instead of sending your real IP via the HTTP_X_FORWARDED_FOR header, it dispatches the proxy’s IP or just leaves it empty. While an anonymous proxy can be useful in maintaining your privacy, it can still be detected and prevented from accessing web pages.
Therefore, if you are using a free or even a paid proxy rotator, you should go for elite proxies.
Wrapping up
Creating a proxy rotator in Python is not complicated. After generating random proxies, you can build a logic that uses the proxies to scrape data from websites.
Importantly, when deploying your Python proxy rotator, there are some things you need to keep in mind to ensure the success of the data extraction process. For example, using predictable IP addresses or relying on unreliable proxies could lead to undesirable results.
Nonetheless, with a versatile and easy-to-use tool like Zenscrape, you can carry out advanced Python web scraping tasks without any hassles. It has a powerful web scraping API that directly returns the HTML markup of any modern web page, allowing you to extract information confidently.
Furthermore, instead of rotating IP addresses manually, Zenscrape does the proxy management for you automatically. It’s the tool you need to make the most of data extraction from online resources.
Happy scraping!
Disclaimer:
All articles are for learning purposes only in order to demonstrate different techniques of developing web scrapers. We do not take responsibility for how our code snippets are used and can not be held liable for any detrimental usage.