

Web scraping has revolutionized how we gather information from the internet. Hence, enabling us to extract valuable data from websites efficiently. However, the data obtained through web scraper is often unstructured and challenging to work with. This is where data parsing comes in. Data parsing is a crucial step in the web scraping process that involves analyzing and extracting relevant information from the scraped data.
In this blog, we will delve into data parsing in web scraping. Furthermore, exploring its significance and how it differs from data scraping. We will also discuss some of the best parsing libraries and tools commonly used in web scraping projects. These are Zenscrape web scraper, Cheerio and Puppeteer, Beautiful Soup, Rvest, Nokogiri, and HTMLAgilityPack.
Furthermore, we will guide you on building your web scraper and parser. Hence, providing insights into the techniques and tools required to extract and parse data from websites efficiently. Stay tuned to explore the fascinating world of data parsing in web scraping and discover how it can empower your data extraction endeavors.

What is Data Parsing?
Data parsing refers to the process of analyzing and extracting relevant information from raw, unstructured data obtained through web scraping. It involves understanding the structure and content of the data and extracting specific data fields for further use.
For example, in a web scraping scenario, data parsing can involve extracting product names, prices, descriptions, or images from an e-commerce website. Parsing the data can transform it into a structured format, such as CSV or JSON. Hence, making it easier to analyze, store, and utilize in various applications, such as data analysis, machine learning, or database management.
What Is The Difference Between Data Scraping and Data Parsing?
Data scraping is the process of extracting data from websites, while data parsing involves analyzing and organizing the extracted data. When developing a web scraper, the initial step involves accessing website information by sending a request to the server and downloading the raw HTML file. However, this HTML data is not easily readable or usable.
Data parsing plays a crucial role in web scraping. It involves transforming the HTML into a parse tree. Hence, enabling us and our teams to navigate and extract the specific information relevant to our objectives.

Let’s take a look at examples.
Example of raw HTML data
```html
<html>
<head>
<title>Sample Website</title>
</head>
<body>
<h1>Welcome to Sample Website</h1>
<div class="article">
<h2>Article 1</h2>
<p>This is the first article content.</p>
</div>
<div class="article">
<h2>Article 2</h2>
<p>This is the second article content.</p>
</div>
</body>
</html>
```Example of parsed data
```json
{
"title": "Sample Website",
"articles": [
{
"title": "Article 1",
"content": "This is the first article content."
},
{
"title": "Article 2",
"content": "This is the second article content."
}
]
}
```In this example, the raw HTML data represents a simple webpage with a title and two articles. By parsing the HTML data, we extract the relevant information and transform it into a structured format. The parsed data is represented in JSON format, where we have the website title and an array of articles, each containing the article title and content. This structured data can be efficiently utilized for further analysis, storage, or presentation.
What Are the Best Parsing Libraries for Web Scraping?
Here are some best tools for web scraping and data parsing.
Zenscrape
Zenscrape stands out as one of the market’s best and most reliable data scrapers and parsers. With its powerful API, Zenscrape offers a user-friendly and efficient solution for web scraping needs. It allows developers to extract data from websites effortlessly. Hence, handling challenges such as IP blocking, CAPTCHA bypassing, and JavaScript rendering.
Zenscrape’s robust features enable seamless integration into various applications and workflows. Hence, allowing for the retrieval of structured data from HTML and JSON sources.
Additionally, it primarily focuses on retrieving data rather than directly providing parsing capabilities. Therefore, this reliable data scraper allows developers to utilize other popular parsing libraries or tools.
Beautiful Soup
Beautiful Soup emerges as an exceptional parsing library capable of handling various HTML files and transforming them into parse trees. One of Beautiful Soup’s standout advantages is its built-in encoding handling, automatically converting incoming documents to Unicode and outgoing documents to UTF-8. This simplifies the process of exporting data into different formats.
To illustrate, consider the following example of initiating Beautiful Soup in Python:
```python
import csv
import requests
from bs4 import BeautifulSoup
url = 'https://www.indeed.com/jobs?q=web+developer&l=New+York'
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
results = soup.find(id='resultsCol')
```Rvest
Rvest is a specialized package crafted to simplify web scraping endeavors in R programming. Leveraging the power of Magrittr, Rvest enables the creation of expressive and easily understandable code using the “>” operator. Thereby, enhancing development and debugging efficiency.
To augment the functionality of your script further, you have the option to incorporate Dplyr, which facilitates seamless data manipulation with a consistent set of verbs such as select(), filter(), and summarise(). Consider the following example:
```R
link <- "https://www.imdb.com/search/title/?title_type=feature&num_votes=25000&genres=adventure"
page <- read_html(link)
titles <- page %>%
html_nodes(".lister-item-header a") %>%
html_text()
```Nokogiri
Nokogiri, a highly popular gem in Ruby for web scraping and parsing HTML and XML files, has gained significant traction with over 300 million downloads. Benefiting from Ruby’s widespread usage and active community, Nokogiri enjoys extensive support and a wealth of tutorials. Hence, making it easily accessible to newcomers. Here is an example of Nokogiri.
require 'httparty'require 'nokogiri'require 'byebug'def scraper url = "https://www.newchic.com/hoodies-c-12200/?newhead=0&mg_id=2&from=nav&country=223&NA=0" unparsed_html = HTTParty.get(url) page = Nokogiri::HTML(unparsed_html) products = Array.new product_listings = page.css('div.mb-lg-32')
How To Build Your Web Scraper & Parser?
Building web scraping software has become easier with Zenscrape. Let’s check how you can achieve it.
- Create an account at Zenscrape and get your API key.
- Get the page URL that you want to scrape. Then, add it to the code given below.
import requests
headers = {
"apikey": "YOURAPIKey"
}
params = (
("url","https://www.deere.com/en/index.html"),
);
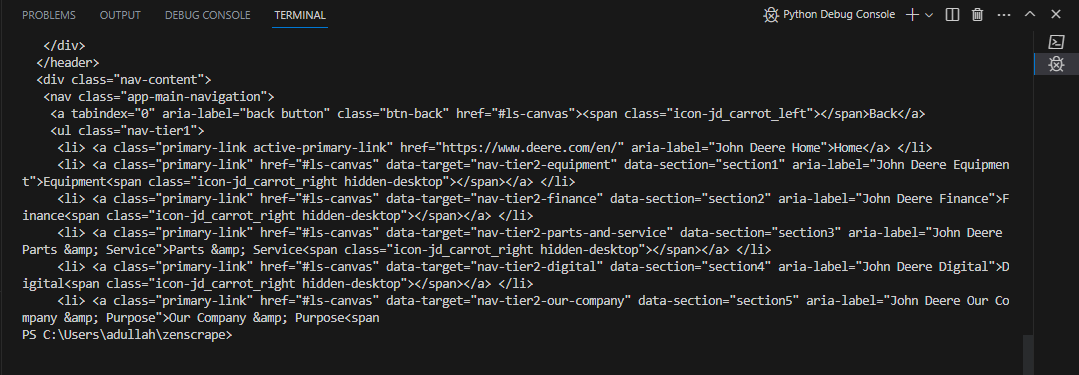
response = requests.get('https://app.zenscrape.com/api/v1/get', headers=headers, params=params);
print(response.text)- It will give you the following response since you have scraped data successfully.

Conclusion
Data parsing plays a pivotal role in web scraping by transforming raw, unstructured data into a structured format that is easier to analyze, manipulate, and utilize. Through the process of data parsing, extracted information can be organized and extracted into specific data fields. Hence, making it more accessible and meaningful.
We explored the difference between data scraping and data parsing. Furthermore, highlighting the significance of parsing libraries in web scraping tasks. Several popular parsing libraries, such as Beautiful Soup, Rvest, Nokogiri, and Zenscrape, were introduced as valuable tools for data parsing. By understanding and implementing data parsing techniques, web scrapers can unlock the full potential of the scraped data for various applications and insights.

FAQs
What Is Web Scraping?
Web scraping is the automated process of extracting data from websites, enabling retrieval and analysis of valuable information.
What Is Web Scraping and How to Do It?
Web scraping is the process of extracting data from websites using automated tools. It involves sending HTTP requests, parsing HTML or JSON responses, and extracting desired information using libraries like BeautifulSoup or Scrapy.
Is Web Scraping Easy?
Web scraping can be both easy and challenging, depending on the complexity of the target website and the desired data extraction.
What Is an Example of Web Scraping?
An example of web scraping is extracting product information from an e-commerce website for market analysis or price comparison.