

Web scraping technology is a very important and life-saving technology that has entered our lives with the development of technology. With a web scraping project, both businesses and developers today obtain the data they want programmatically from web pages. The number of data scraping Python applications is therefore increasing. These applications mostly use a web scraping API or a Python library for web scraping.
Many businesses today have their own Python web scraper implementations. With these applications, businesses and developers target extracting data with seamless and unblock-able connection from any web page. In this Python web scraping tutorial we will list what they need to do in Python code to be able to scrape data seamlessly and unblock-ablely.
Getting Unblock-able Data with Python Web Scraping
Web scraping is the process of collecting and analyzing large amounts of data from the internet. The Internet offers a great source of data in many industries and fields. Accessing this data presents many opportunities for businesses and developers. Web scraping helps businesses gain important information such as doing market research, competitive analysis, tracking customer feedback, making price comparisons, and spotting trends. Moreover, web scraping is also important for keeping up with innovations in industries, understanding market trends, reaching potential customers, gaining competitive advantage, and making strategic decisions.
Explore the step-by-step Python web scraping tutorial.
While there are many reasons businesses and developers should develop a web scraping application, it is important to develop it carefully. In this section, we will talk about the ways they can follow in order not to be blocked by the target websites and to have an uninterrupted data flow.
Sending Requests with Headers and User-Agent
To bypass the website blocks of businesses and developers, they need to configure information like headers and user-agent. These help the web scraping app hide that it is a scraper and make it look like a web app. Some websites can detect web scraping bots or automated requests and impose blocks. To avoid this situation, you can specify a browser-like header and user agent and add this information to the request header to perform data scraping.
Sample Code:
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Accept-Language': 'en-US,en;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive'
}
response = requests.get('https://example.com', headers=headers)
# Continue to data scrapingAdding Time Delay Between Requests
One of the reasons a website detects web scraping bots is because an application makes quick requests in a row. This is important for websites because it can prevent serving data to other users. To avoid this situation, developers can add a wait time between HTTP requests in their web scraping applications. This makes it difficult for target websites to detect web scraping practices and provides unblock-able data scraping.
Sample Code:
import requests
import time
for i in range(10):
response = requests.get('https://example.com')
# Continue to data scraping
time.sleep(1)Using Proxy
Using a proxy is a method that we can see in almost every web scraping Python tutorial nowadays. Using a proxy is an extremely effective method when scraping HTML code from the target website with a web scraping application. Proxy servers can be used to hide IP addresses and send requests from various locations. Developers can also use different proxy servers during data scraping to avoid being blocked in their web scraping process. This way they can bypass the blocks by making each request from a different IP address.
Meet proxy rotation to avoid IP blocking!
Sample Code:
import requests
proxies = {
'http': 'http://your-proxy-ip:port',
'https': 'https://your-proxy-ip:port',
}
response = requests.get('https://example.com', proxies=proxies)
# Continue to data scrapingUsing CAPTCHA Solver
Recently, many websites have used CAPTCHA validation to prevent access by web scraping bots. In this case, developers must use various methods to resolve CAPTCHA and pass validation for unblock-able data scraping Python. For example, they can recognize text in a CAPTCHA image using an OCR (Optical Character Recognition) library such as pytesseract, or integrate custom CAPTCHA analysis services.
Sample Code:
import requests
import pytesseract
from PIL import Image
response = requests.get('https://example.com/captcha_image.jpg')
with open('captcha_image.jpg', 'wb') as f:
f.write(response.content)
captcha_image = Image.open('captcha_image.jpg')
captcha_text = pytesseract.image_to_string(captcha_image)
# Verify using CAPTCHA text and perform data scrapingUsing a Web Scraping API
Using a web scraping API is generally the most preferred method for web scraping processes. The main reason for this is a web scraping API can scrape HTML documents from any web page using the above methods.
There are many web scraping APIs that developers can easily do this with. Among them, the best web scraping API that provides unblock-able data scraping is Zenscrape API. This API has a very powerful infrastructure that enables data scraping from target websites as reait-ime. It also has a proxy pool with millions of IP addresses. It also offers location-based web scraping and automatic proxy rotation for unblock-able data scraping. Furthermore, it delivers in JavaScript rendering.
Zenscrape API has a very innovative pricing policy. It offers a free plan that allows it to get ahead of its competitors, and this plan has a very comprehensive limit of 1,000 API calls per month. In addition, their paid plan is quite comprehensive and affordable.
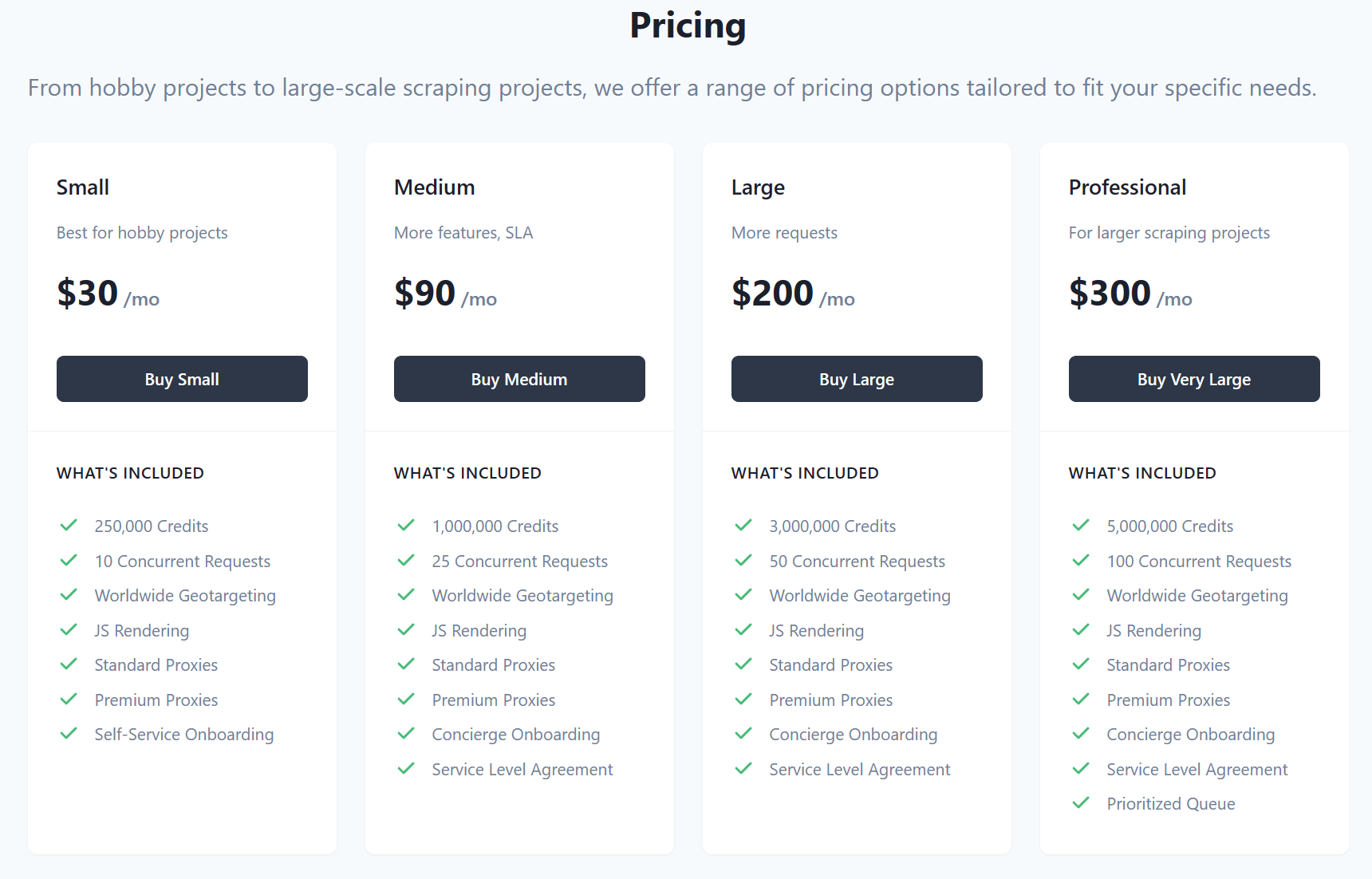
Finally, this API integrates easily into all current programming languages. It also supports all front-end frameworks.
Sample Code:
import requests
headers = {
"apikey": "YOUR-APIKEY"
}
param = (
("url","https://httpbin.org/ip"),
("premium","true"),
("country","de"),
("render","true"),
);
response = requests.get('https://app.zenscrape.com/api/v1/get', headers=headers, params=params);
print(response.text)Conclusion
As a result, the use of web scraping applications has become quite common, which developers and businesses use for many reasons. Many users use these apps for price tracking, data analysis, strategizing, and more. It is very important for the continuity of business processes that these applications, whose use cases are increasing, are developed by considering unblock-able approaches.
Try the best web scraping API of 2023, and extract data from web pages with unblock-able and seamless data scraping.
FAQs
Q: What is The Best Web Scraping API for Unblock-able Scraping?
A: There are many web scraper APIs available in the market today that offer web scraping. However many of them do not offer unblock-able data scraping to their users. The best unblock-able data scraping API on the market is the Zenscrape API. This API has a proxy pool with millions of IP addresses and automatically provides proxy rotation.
Q: How Do I Scrape Data from a Web Page Using Python Programming Language?
A: To scrape data from a web page with the Python programming language, you can get the source code of the web page by making a request with the phrase “import requests”. You can access the data you want using elements such as HTML tags and a href attribute and save this data in formats such as a CSV file or Python files.
Q: What is the Role of “import requests” in Data Scraping Python?
A: The phrase “import requests” is used to import a library used in data scraping in Python. This library is a fairly common tool used to send HTTP requests and retrieve the content of web pages.
Q: What are the Advantages of Using Proxies in Data Scraping Python?
A: The advantages of using proxy for data scraping are:
- It provides anonymity by hiding your IP address.
- Bypass blocking by sending requests from different IP addresses.
- Provides a wider variety of geographic locations.
- Improves performance on high-traffic websites.