

Using rotating proxies for web scraping is a good way of avoiding being throttled or blocked. With a Node proxy rotator, you can hide your real IP address and bypass the anti-scraping measures implemented by most popular websites, which ensures you harvest data without any worries.
In this article, we’ll demonstrate how to create a simple proxy rotator in Node.js and make the most of your data scraping efforts.
Looking for a Python tutorial? Build a proxy rotator with Python – complete guide
Prerequisites
Here are the resources we’ll be using in this project:
- https://sslproxies.org/—to hide our real IP address, we’ll fetch some free HTTPS proxies from this website. It has a huge list of IP addresses and their corresponding port numbers that are updated every 10 minutes. You can also get a proxy from anywhere else.
Here is a screenshot of the website:
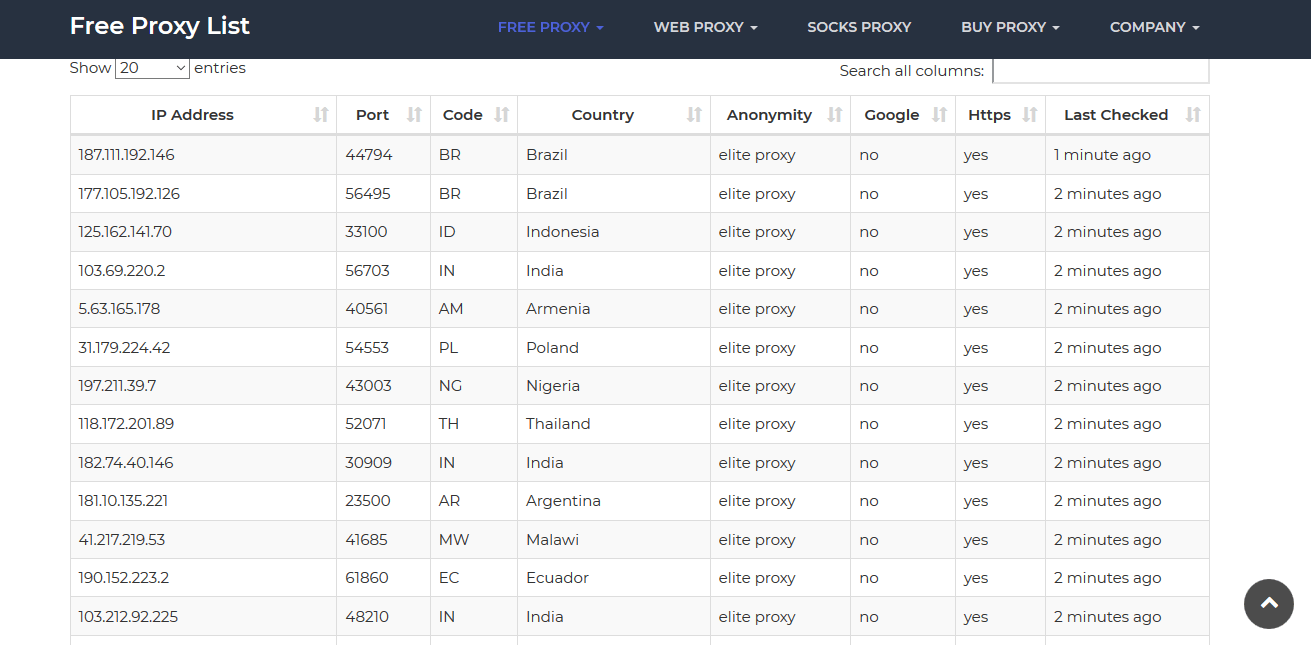
- Request—we’ll use this Node.js package for making HTTP calls and scraping the content of websites.
- Cheerio—we’ll use this Node.js package for interpreting and analyzing the content of web pages using jQuery-like syntax.
Setting up the project
Foremost, let’s download Node.js from its website and install it on our machine (you can choose the installation option that suits your platform’s specifications).
Afterward, let’s create a directory called ScrapingTutorial that will hold the files for this Node proxy rotator tutorial.
Since we’re starting a new project, let’s create a package.json file that will specify the dependencies we’ll use in this project. A simple way of creating the file is to open the Command Prompt, navigate to the project’s root directory, and run the npm init command.
Here is the code for the package.json file:
{
"name": "scrapingtutorial",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC",
"dependencies": {
"cheerio": "latest",
"request": "latest"
}
}You’ll notice that we specified request and cheerio as the dependencies for this IP rotator project.
Then, to install the stated dependencies, we’ll run the npm install command on the Command Prompt:
C:\Users\OPIDI\Desktop\ScrapingTutorial>npm installConsequently, the node_modules directory, which has the specified dependencies and other Node packages, will be added to the project. The package-lock.json file, which contains details of the downloaded packages, will also be added to the project.
Finally, let’s create another file called index.js that will contain the programming logic for the proxy rotator in Node.
Here is a screenshot of our project’s structure on the Visual Studio Code editor:

Retrieving proxies
Now, let’s make our hands dirty by delving into some code!
To begin with, let’s use the Node’s built-in require function to include the packages we’ll use in the index.js file.
const request = require('request');
const cheerio = require('cheerio');Next, let’s use the request function to make http requests and grab a list of IP addresses and their corresponding port numbers from the sslproxies website.
Here is the code:
This is what is happening in the code above:
- In the first parameter of the function, we specified the URL of the website we want to grab its contents
- In the second parameter, we specified a callback function and its associated arguments
- If there are no errors and the request is successful, we used Cheerio to the load the HTML we received from the response
- Since the details of IP addresses and port numbers we need to scrape are present within the HTML <td> tags on the sslproxies website, we used Cheerio’s selectors to find the data in the first column and the second column, respectively.
- We used the .each method to iterate over the generated Cheerio object and execute a callback function for every selected element. Notice that we used the .text method to write the grabbed data into arrays.
Then, let’s run the following command on the terminal to execute the code:
C:\Users\OPIDI\Desktop\ScrapingTutorial>node index.jsConsequently, we get a list of IP addresses and their corresponding port numbers, which we’ll use to create the free proxy list rotator.
Here is the screenshot (for brevity, we’ve truncated the results):


Randomizing the proxy list
Next, let’s generate a random number between 1 and 100 that we’ll use for referencing the index number of the arrays and retrieving a random IP address from the list. This way, we’ll ensure that we use a different proxy for each request.
Here is the code:
let random_number = Math.floor(Math.random() * 100);Let’s see if we can get a random IP address and its corresponding port number:
console.log(ip_addresses[random_number]);
console.log(port_numbers[random_number]);
As you can see on the screenshot above, we’ve been able to generate a random proxy address from the sslproxies website.
Now, the next challenge is to join the retrieved IP address and port number into the required format.
To achieve this, we’ll use ES6 template literals to interpolate the variables into a single string.
Here is the code:
let proxy = 'http://${ip_addresses[random_number]}:${port_numbers[random_number]}';
console.log(proxy);
If we run the code three times, here is what we get:

As you can see on the screenshot above, we were able to iterate over the list of generated proxies and pick a different proxy in each request; and without using the same proxy two times in a row.
Lastly, let’s wrap the entire IP rotator code into a function called proxyGenerator():
Scraping websites using the Node proxy rotator
After illustrating how to generate random proxies in Node.js, let’s now see how you can use them to scrape the content of websites successfully.
For this demonstration, we’ll try to scrape the headings of this blog post, which are defined by the <h2> tags.
To use our generated proxies, we’ll provide an object of options in the first argument of the request function. Then, we’ll specify a proxy option and call the previously created proxyGenerator() function, which produces random proxies.
Here is the code:
Here is the screenshot of the results:

It worked!
That’s how you can create a simple proxy rotator in Node.js and extract the content of websites without experiencing blockades.
5 tips for rotating proxies successfully
However, even after you’ve created your own IP proxy rotator, there are things you need to keep in mind to ensure you always stay below the radar and avoid being banned.
Here are five tips to ensure your data extraction efforts yield the required results.
1. Choose reliable free proxy services
If you are using a free service to build a free proxy list rotator, you may experience delays and disruptions. Above all, most of the free proxy services have invalid IP addresses, are overcrowded, and may not offer the desired anonymity.
Therefore, you should perform sufficient background checks and choose a reliable service that can meet your scraping goals without significant hiccups.
2. Opt for a premium service
If you intend to carry out advanced, extensive data extraction tasks, then you should opt for a premium proxy rotator. While the free IP rotators may get the job done, paying a few dollars to a good premium provider will guarantee you a high-quality service, minimal interruptions, and optimal security.
Therefore, if you want to scrap hundreds of web pages fast and without being detected, a premium service may best meet your needs.
3. Avoid predictable IP addresses
If you are using a free or a paid proxy service, you should avoid using rotating IP addresses that are in a predictable format. Most anti-scraping tools can detect that a series of IP addresses belong to the same group or are in a continuous range, and ban them from accessing content.
Here are examples of rotating IP addresses that can point to some abnormal activities:
194.242.98.251
194.242.98.253
194.242.98.254
194.242.98.255
4. Use IP rotation with user agent rotation
While rotating IP addresses can assist you to scrape web content successfully, some anti-scraping tools can still identify such activities and prevent the exfiltration of data.
Therefore, combining IP rotation with user agent rotation can significantly reduce the chances of being detected. If you incorporate random user agents, it’ll appear as if your requests are coming from multiple browsers, just like normal users.
5. Choose elite proxies
If you are using a free or a paid proxy service, choosing an elite proxy provides you with the best way of sidestepping restrictions and ensuring you harvest online data successfully. While elite proxies work just like any other proxies, they come with other unique additions that offer the absolute highest level of security.
Although the other types of proxies, such as transparent proxies and anonymous proxies, can still get the job done, they can easily disclose the details of your IP address.
Zenscrape Proxies offers premium residential proxies form a range of over 8.5M IP addresses starting at 65$ / month. Register for free
Node proxy rotator – Wrapping up
In conclusion, building a proxy rotator in Node.js is not difficult. After creating the logic that generates random proxies, you can use the proxies to harvest the content of websites without being blocked.
Notably, when deploying your Node proxy rotator, you should use random and unique IP addresses, incorporate rotating user agents, and make other considerations to avoid raising the red flag.
If you are looking for a top-notch, powerful, and easy-to-use tool for scraping online data, then Zenscrape can best meet your needs. It has an intuitive web scraping API that returns the HTML markup of any web page, enabling you to gather data reliably.
Additionally, Zenscrape does proxy management for you automatically, which saves you the hassle of rotating IP addresses manually. It takes care of everything that complicates data extraction.
Frequently Asked Questions
Q: What is a simple proxy switcher?
A: A simple proxy switcher is a tool or script that automatically rotates between different proxy servers to hide the user’s real IP address and bypass restrictions or blocks.
Q: How does a proxy rotator help with web scraping?
A: A proxy rotator helps with web scraping by allowing the scraper to use different IP addresses, reducing the chances of being blocked or throttled by websites.
Q: What are the benefits of using a proxy rotator for web scraping?
A: Using a proxy rotator for web scraping helps to avoid IP bans, increases anonymity, and allows for scraping large amounts of data without interruptions.
Q: Can a proxy rotator be used for other purposes besides web scraping?
A: Yes, a proxy rotator can be used for various purposes, such as accessing geo-restricted content, ensuring online privacy, and bypassing internet censorship.
Happy scrapping!
Disclaimer:
All articles are for learning purposes only to demonstrate different techniques for developing web scrapers. We do not take responsibility for how our code snippets are used and can not be held liable for any detrimental usage.